本系列为《模式识别与机器学习》的读书笔记。
一,多元高斯分布
考虑⾼斯分布的⼏何形式,⾼斯对于 $\boldsymbol{x}$ 的依赖是通过下⾯形式的⼆次型:
其中,$\Delta$ 被叫做 $\boldsymbol{\mu}$ 和 $\boldsymbol{x}$ 之间的马⽒距离(Mahalanobis distance)。 当 $\boldsymbol{\Sigma}$ 是单位矩阵时,就变成了欧式距离。对于 $\boldsymbol{x}$ 空间中这个⼆次型是常数的曲⾯,⾼斯分布也是常数。
现在考虑协⽅差矩阵的特征向量⽅程:
其中 $i = 1,\dots , D$。由于 $\boldsymbol{\Sigma}$ 是实对称矩阵,因此它的特征值也是实数,并且特征向量可以被选成单位正交的,即:
其中 $I_{ij}$ 是单位矩阵的第 $i, j$ 个元素,满⾜:
协⽅差矩阵 $\boldsymbol{\Sigma}$ 可以表⽰成特征向量的展开的形式:
协⽅差矩阵的逆矩阵 $\boldsymbol{\Sigma}^{-1}$ 可以表⽰成特征向量的展开的形式:
⼆次型公式(2.30)即可表示为:
其中,$y_{i}^{2} = \boldsymbol{u_i^T} (\boldsymbol{x} - \boldsymbol{\mu})$ 。
把 $\{y_i\}$ 表⽰成单位正交向量 $\boldsymbol{\mu_i}$ 关于原始的 $x_i$ 坐标经过平移和旋转后形成的新的坐标系。定义向量 $\boldsymbol{y} = (y_1,\dots, y_D)^T$ ,即有:
其中 $\boldsymbol{U}$ 是⼀个矩阵,它的⾏是向量 $\boldsymbol{u}_{i}^{T}$ 。从公式(2.32)可以看出 $\boldsymbol{U}$ 是⼀个正交矩阵, 即它满⾜性质 $\boldsymbol{U}\boldsymbol{U}^T = \boldsymbol{I}$ ,因此也满⾜ $\boldsymbol{U}^T \boldsymbol{U} = \boldsymbol{I}$ ,其中 $\boldsymbol{I}$ 是单位矩阵。
⼀个特征值严格⼤于零的矩阵被称为正定(positive definite)矩阵。偶尔遇到⼀个或者多个特征值为零的⾼斯分布,那种情况下分布是奇异的,被限制在 了⼀个低维的⼦空间中。如果所有的特征值都是⾮负的,那么这个矩阵被称为半正定(positive semidefine)矩阵。
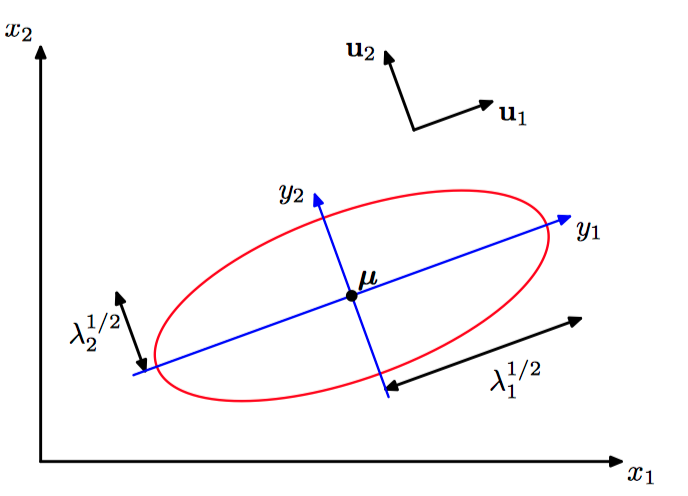
如图2.12,红⾊曲线表⽰⼆维空间 $\boldsymbol{x} = (x_1 , x_2)$ 的⾼斯分布的常数概率密度的椭圆⾯, 它表⽰的概率密度为 $\exp(−\frac{1}{2})$,值是在 $\boldsymbol{x} = \boldsymbol{\mu}$ 处计算的。椭圆的轴由协⽅差矩阵的特征向量 $\mu_i$ 定义,对应的特征值为 $\lambda_i$ 。
现在考虑在由 $y_i$ 定义的新坐标系下⾼斯分布的形式。 从 $\boldsymbol{x}$ 坐标系到 $\boldsymbol{y}$ 坐标系, 我们有⼀个 Jacobian矩阵 $\boldsymbol{J}$ ,它的元素为:
其中 $U_{ji}$ 是矩阵 $\boldsymbol{U}^T$ 的元素。使⽤矩阵 $\boldsymbol{U}$ 的单位正交性质,我们看到 Jacobian矩阵 ⾏列式的平⽅为:
从而可知,$|\boldsymbol{J}|=1$ ,并且,⾏列式 $|\boldsymbol{\Sigma}|$ 的协⽅差矩阵可以写成特征值的乘积,因此:
因此在 $\boldsymbol{y}$ 坐标系中,⾼斯分布的形式为:
这是 $D$ 个独⽴⼀元⾼斯分布的乘积。
在 $\boldsymbol{y}$ 坐标系中,概率分布的积分为:
⾼斯分布下 $\boldsymbol{x}$ 的期望为:
其中,$\boldsymbol{z = x - \mu}$ 。注意到指数位置是 $\boldsymbol{z}$ 的偶函数,并且由于积分区间为 $(−\infty, \infty)$,因此在因⼦ $(\boldsymbol{z + \mu})$ 中的 $\boldsymbol{z}$ 中的项会由于对称性变为零。因此 $\mathbb{E}[\boldsymbol{x}] = \boldsymbol{\mu}$ 。称 $\boldsymbol{\mu}$ 为⾼斯分布的均值。
现在考虑⾼斯分布的⼆阶矩。对于多元⾼斯分布,有 $D^2$ 个由 $\mathbb{E}[x_i x_j]$ 给出的⼆阶矩,可以聚集在⼀起组成矩阵 $\mathbb{E}[\boldsymbol{x}\boldsymbol{x}^T ]$。
其中,$\boldsymbol{z = x - \mu}$ ,$\boldsymbol{z} = \sum_{j=1}^{D} y_i \boldsymbol{u_j}$ ,$y_i = \boldsymbol{u_j}^{T}\boldsymbol{z}$ 。
由此可以推导出:
随机变量 $\boldsymbol{x}$ 的协⽅差(covariance),定义为:
对于⾼斯分布这⼀特例,我们可以使⽤ $\mathbb{E}[\boldsymbol{x}] = \boldsymbol{\mu}$ 以及公式(2.45)的结果,得到:
由于参数 $\boldsymbol{\Sigma}$ 公式了⾼斯分布下 $\boldsymbol{x}$ 的协⽅差,因此它被称为协⽅差矩阵。
二,条件⾼斯分布
多元⾼斯分布的⼀个重要性质:如果两组变量是联合⾼斯分布,那么以⼀组变量为条件, 另⼀组变量同样是⾼斯分布。
假设 $\boldsymbol{x}$ 是⼀个服从⾼斯分布 $\mathcal{N}(\boldsymbol{x} | \boldsymbol{\mu}, \mathbf{\Sigma})$ 的 $D$ 维向量。我们把 $\boldsymbol{x}$ 划分成两个不相交的⼦集 $\boldsymbol{x}_a$ 和 $\boldsymbol{x}_b$ 。 不失⼀般性, 令 $\boldsymbol{x}_a$ 为 $\boldsymbol{x}$ 的前 $M$ 个分量, 令 $\boldsymbol{x}_b$ 为剩余的 $D − M$ 个分量,因此
同理,对应的对均值向量 $\boldsymbol{\mu}$ 的划分,即
协⽅差矩阵 $\boldsymbol{\Sigma}$ 为:
注意,协⽅差矩阵的对称性 $\boldsymbol{\Sigma} ^T= \boldsymbol{\Sigma}$ 表明 $\boldsymbol{\Sigma}_{aa}$ 和 $\boldsymbol{\Sigma}_{bb}$ 也是对称的,⽽ $\boldsymbol{\Sigma}_{ba} = \boldsymbol{\Sigma}_{ab}^{T}$ 。
在许多情况下,使⽤协⽅差矩阵的逆矩阵⽐较⽅便,也叫精度矩阵(precision matrix),即:
精度矩阵的划分形式
关于分块矩阵的逆矩阵的恒等式:
其中, $\boldsymbol{M = (A-BD^{-1}C)^{-1}}$ ,$\boldsymbol{M}^{-1}$ 被称为公式(2.50)左侧矩阵关于⼦矩阵 $\boldsymbol{D}$ 的舒尔补(Schur complement)。
由以上公式和相关结论可以推导出条件概率分布 $p(\boldsymbol{x}_a | \boldsymbol{x}_b)$ 的均值和协⽅差的表达式:
三,边缘⾼斯分布
对于边缘高斯分布:
同条件高斯分布一样,可以推导出边缘概率分布 $p(\boldsymbol{x}_a)$ 的均值和协⽅差的表达式:
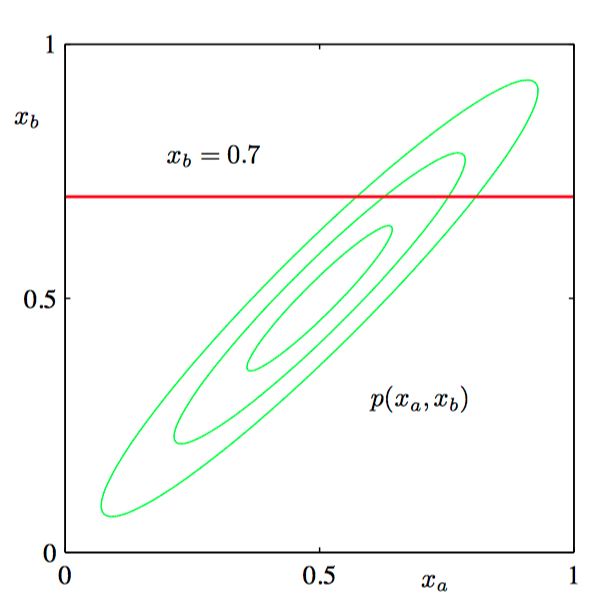
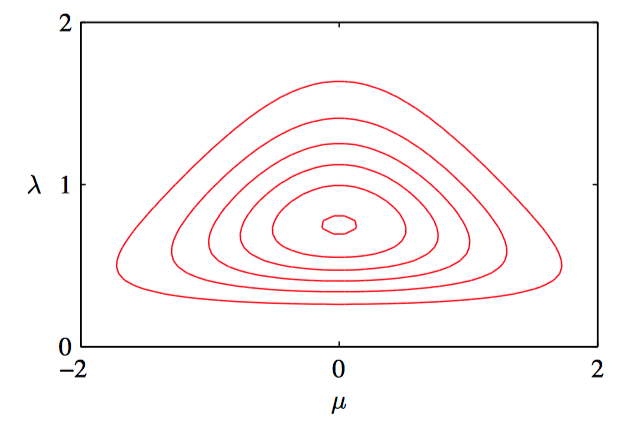
如图2.13,两个变量上的⾼斯概率分布 $p(x_a , x_b)$ 的轮廓线。
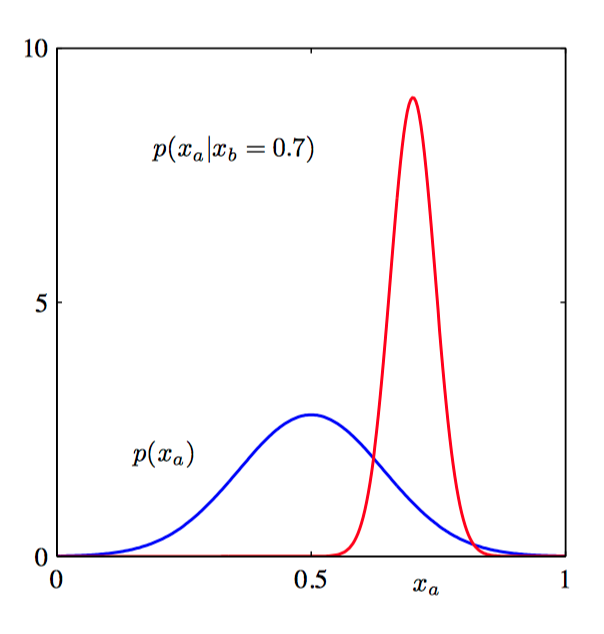
如图2.14,边缘概率分布 $p(x_a)$(蓝⾊曲线)和 $x_b = 0.7$ 的条件概率分布 $p(x_a|x_b)$(红⾊曲线)。
四,⾼斯变量的贝叶斯定理
令边缘概率分布和条件概率分布的形式:
其中,$\boldsymbol{\mu}$ , $\boldsymbol{A}$ 和 $\boldsymbol{b}$ 是控制均值的参数,$\boldsymbol{\Lambda}$ 和 $\boldsymbol{L}$ 是精度矩阵。如果 $\boldsymbol{x}$ 的维度为 $M$ ,$\boldsymbol{y}$ 的维度为 $D$,那么矩阵 $A$ 的⼤⼩为 $D \times M$ 。
⾸先,我们寻找 $\boldsymbol{x}$ 和 $\boldsymbol{y}$ 的联合分布的表达式。令
然后考虑联合概率分布的对数:
可以推导出,$\boldsymbol{z}$ 上的⾼斯分布的精度矩阵(协⽅差的逆矩阵)为:
从而,$\boldsymbol{z}$ 上的⾼斯分布的均值和协⽅差的表达式:
边缘分布 $p(\boldsymbol{y})$ 的均值和协⽅差为:
条件分布 $p(\boldsymbol{x}|\boldsymbol{y})$ 的均值和协⽅差为:
五,⾼斯分布的最⼤似然估计
给定⼀个数据集 $\boldsymbol{X} = (\boldsymbol{x}_1, \dots, \boldsymbol{x}_N)^T$ , 其中观测 $\{\boldsymbol{x}_n\}$ 假定是独⽴地从多元⾼斯分布中抽取的。我们可以使⽤最⼤似然法估计分布的参数。对数似然函数为:
令对数似然函数关于 $\mu$ 的导数为零,可以求得均值的最大似然估计:
方差的最大似然估计:
从而,
六,顺序估计
考虑公式(2.68)给出的均值的最⼤似然估计结果 $\boldsymbol{\mu}_{ML}$ 。 当它依赖于第 $N$ 次观察时, 将记作 $\boldsymbol{\mu}_{ML}^{(N)}$ 。如果想分析最后⼀个数据点 $\boldsymbol{x}_N$ 的贡献,即有:
考虑⼀对随机变量 $\theta$ 和 $z$ , 它们由⼀个联合概率分布 $p(z, \theta)$ 所控制。已知 $\theta$ 的条件下, $z$ 的条件期望定义了⼀个确定的函数 $f(\theta)$ ,叫回归函数,形式如下:
如图2.15,回归函数 $f(\theta)$ 。
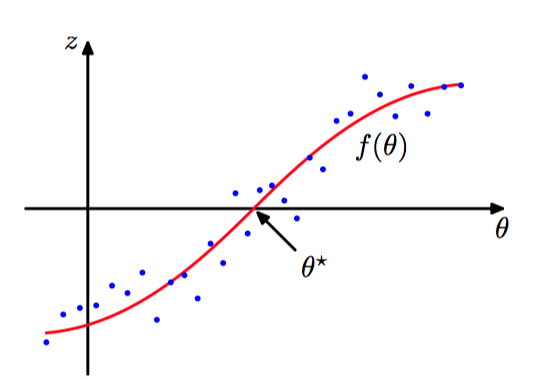
⽬标是寻找根 $\theta^{∗}$ 使得 $f(\theta^{∗}) = 0$。 如果有观测 $z$ 和 $\theta$ 的⼀个⼤数据集, 那么可以直接对回归函数建模, 得到根的⼀个估计。 但是假设每次观测到⼀个 $z$ 的值, 我们想找到⼀个对应的顺序估计⽅法来找到 $\theta^{∗}$ 。 下⾯的解决这种问题的通⽤步骤由 Robbins and Monro(1951)给出。假定 $z$ 的条件⽅差是有穷的,即:
并且不失⼀般性, 我们也假设当 $\theta \gt \theta^{∗}$ 时 $f(\theta) \gt 0$, 当 $\theta \lt \theta^{∗}$ 时 $f(\theta) \lt 0$,Robbins-Monro 的⽅法定义了⼀个根 $\theta^{∗}$ 的顺序估计的序列,由公式(2.75)给出。
其中 $z(\theta^{(N)})$ 是当 $\theta$ 的取值为 $\theta (N)$ 时 $z$ 的观测值。系数 $\{\alpha_N\}$ 表⽰⼀个满⾜下列条件的正数序列:
根据定义,最⼤似然解 $\theta_{ML}$ 是负对数似然函数的⼀个驻点,因此满⾜:
交换导数与求和,取极限 $N \to \infty$ ,可以寻找最⼤似然解对应于寻找回归函数的根。 于是可以应⽤ Robbins-Monro⽅法,此时它的形式为:
七,⾼斯分布的贝叶斯推断
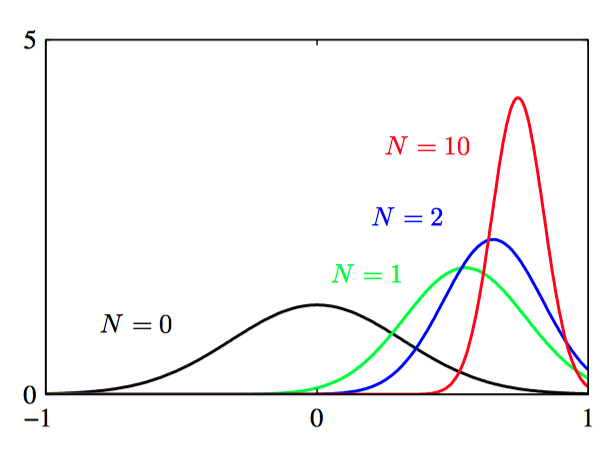
考虑⼀个⼀元⾼斯随机变量 $\mathbf{x}$,我们假设⽅差 $\sigma^2$ 是已知的,其任务是从⼀组 $N$ 次观测 $\mathbf{x}=(x_1,\dots, x_N)^T$ 中推断均值 $\mu$。 似然函数,即给定 $\mu$ 的情况下,观测数据集出现的概率。它可以看成 $\mu$ 的函数,由公式(2.78)给出。
注意:似然函数 $p(\mathbf{x}|\mu)$ 不是 $\mu$ 的概率密度,没有被归⼀化。
如图2.16,在⾼斯分布的情形中,回归函数的形式。
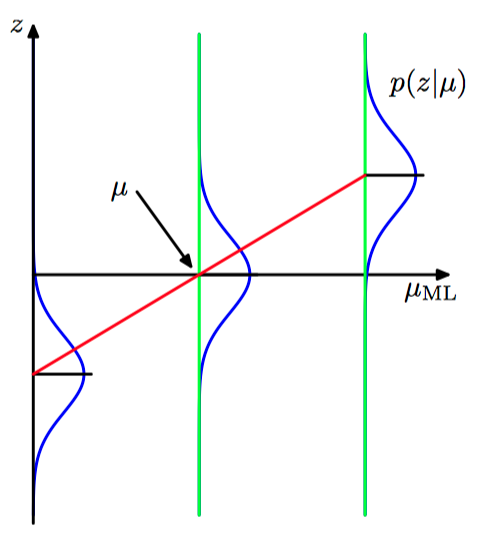
令先验概率分布为:
从⽽后验概率为:
其中,
图2.17,⾼斯分布均值的贝叶斯推断。
现在假设均值是已知的,我们要推断⽅差。令 $\lambda \equiv \frac{1}{\sigma^{2}}$ ,$\lambda$ 的似然函数的形式为:
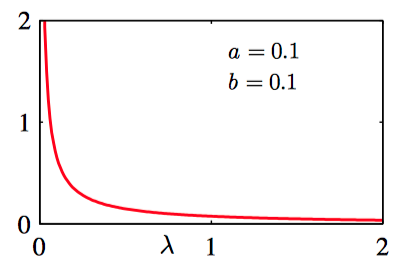
对应的共轭先验因此应该正⽐于 $\lambda$ 的幂指数,也正⽐于 $\lambda$ 的线性函数的指数。这对应于 Gamma分布,定义为:
均值和协⽅差分别为:
如图2.18~2.20,不同的 $a$ 和 $b$ 的情况下 Gamma分布的图像。
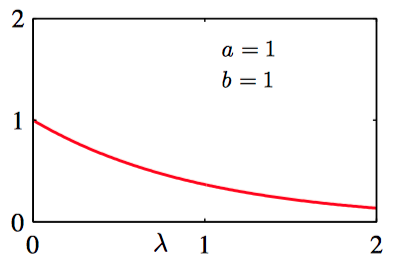
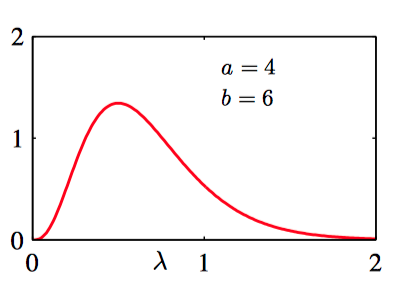
考虑⼀个先验分布 $\text{Gam}(\lambda|a_0,b_0)$。如果乘以公式(2.81)给出的似然函数,那么即可得到后验分布:
我们可以把它看成形式为 $\text{Gam}(\lambda|a_N,b_N)$ 的 Gamma分布,其中
现在假设均值和精度都是未知的。为了找到共轭先验,考虑似然函数对于 $\mu$ 和 $\lambda$ 的依赖关系:
假设先验分布的形式为:
其 中 $c, d$ 和 $\beta$ 都是常数。
归⼀化的先验概率的形式为:
这被称为正态-Gamma分布或者⾼斯-Gamma分布。如图2.21:
对于 $D$ 维向量 $\boldsymbol{x}$ 的多元⾼斯分布 $\mathcal{N}(\boldsymbol{x|\mu, \Lambda}^{−1})$,假设精度已知,则均值 $\boldsymbol{\mu}$ 的共轭先验分布仍然是⾼斯分布。对于已知均值未知精度矩阵 $\boldsymbol{\Lambda}$ 的情形,共轭先验是Wishart分布,定义为:
其中 $\nu$ 被称为分布的⾃由度数量(degrees of freedom),$\boldsymbol{W}$ 是⼀个 $D \times D$ 的标量矩阵,$\operatorname{Tr}(·)$ 表⽰矩阵的迹。归⼀化系数 $B$ 为:
如果均值和精度都是未知的,那么类似于⼀元变量的推理⽅法,共轭先验为:
这被称为正态-Wishart分布或者⾼斯-Wishart分布。
八,学生 $\mathbf{t}$ 分布
如果有⼀个⼀元⾼斯分布 $\mathcal{N}\left(x | \mu, \tau^{-1}\right)$ 和⼀个 Gamma先验分布 $\text{Gam}(\tau|a, b)$,把精度积分出来,便可以得到 $x$ 的边缘分布,形式为:
形如 $p(x|\mu a,b)$ 如下:
称为学生 t 分布(Student's t-distribution)。 参数 $\lambda$ 有时被称为 $\mathbf{t}$ 分布的精度(precision), 即使它通常不等于⽅差的倒数。参数 $\nu$ 被称为⾃由度(degrees of freedom)。如图2.22:
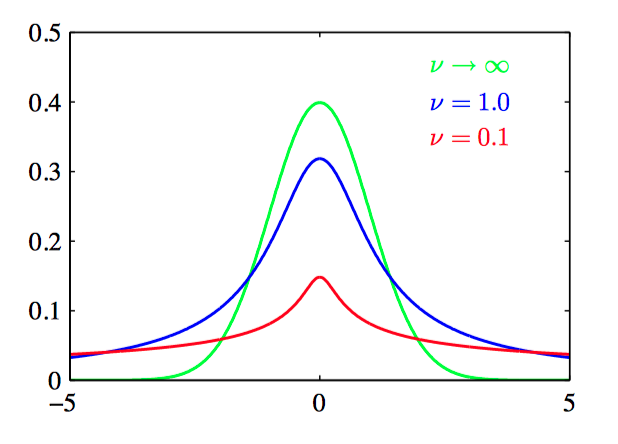
学生 $\mathbf{t}$ 分布的⼀个重要性质:鲁棒性(robustness),即对于数据集⾥的⼏个离群点outlier的出现,分布不会像⾼斯分布那样敏感。
图 2.23,从⼀个⾼斯分布中抽取的30个数据点的直⽅图,以及得到的最⼤似然拟合。红⾊曲线表⽰使⽤ $\mathbf{t}$ 分布进⾏的拟合,绿⾊曲线(⼤部分隐藏在了红⾊曲 线后⾯)表⽰使⽤⾼斯分布进⾏的拟合。由于 $\mathbf{t}$ 分布将⾼斯分布作为⼀种特例,因此它给出了与⾼斯分布⼏乎相同的解。
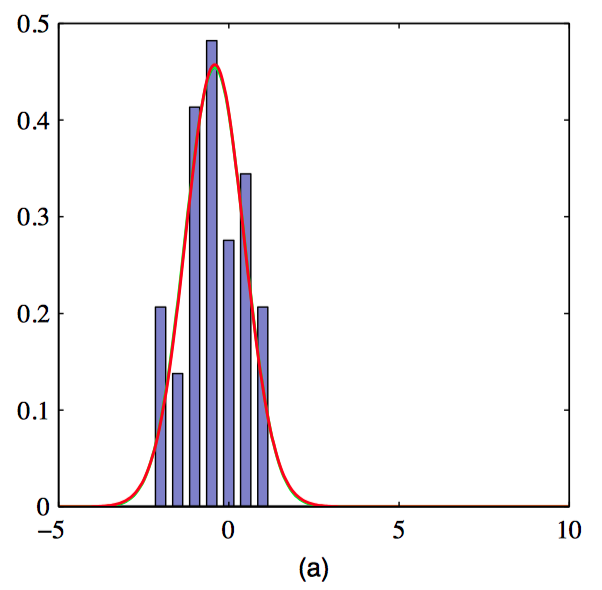
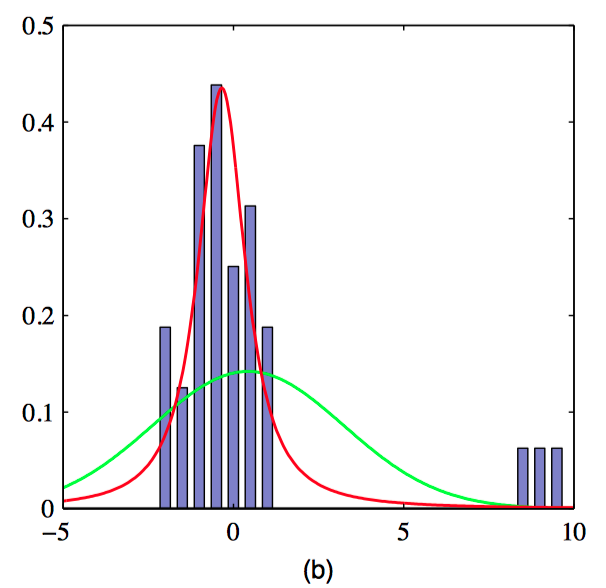
图 2.24,与图2.23同样的数据集,但是多了三个异常数据点。这幅图展⽰了⾼斯分布(绿⾊曲线)是如 何被异常点强烈地⼲扰的,⽽ $\mathbf{t}$ 分布(红⾊曲线)相对不受影响。
推⼴到多元⾼斯分布 $\mathcal{N}(\boldsymbol{x|\mu, \Lambda})$ 来得到对应的多元学生 $\mathbf{t}$ 分布,形式为:
求积分,可得:
其中 $D$ 是 $\boldsymbol{x}$ 的维度,$\Delta^2$ 是平⽅马⽒距离,定义为:
多元变量形式的学生 $\mathbf{t}$ 分布,满⾜下⾯的性质:
1)$\mathbb{E}[\boldsymbol{x}] = \boldsymbol{\mu}$ 如果 $\nu \gt 1$
2)$\text{cov}[\boldsymbol{x}] = \frac{\nu}{\nu-2}\boldsymbol{\Lambda}^{-1}$ 如果 $\nu \gt 2$
3)$\text{mode}[\boldsymbol{x}] = \boldsymbol{\mu}$
九,周期变量
考察⼀个⼆维单位向量 $\boldsymbol{x}_1,\dots,\boldsymbol{x}_N$ , 其中 $||\boldsymbol{x}_n|| = 1$ 且 $n = 1,\dots , N$ , 如图2.25所⽰。
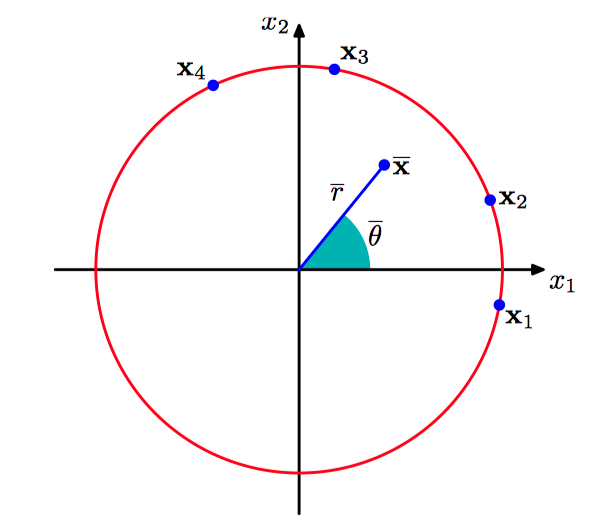
可以对向量 $\{\boldsymbol{x}_n\}$ 求平均,可得
注意,$\bar{\boldsymbol{x}}$ 通常位于单位圆的内部。
$\bar{\boldsymbol{x}}$ 对应的角度 $\bar{\theta}$ 为:
考虑的周期概率分布 $p(\theta)$ 的周期为 $2\pi$ 。$\theta$ 上的任何概率密度 $p(\theta)$ ⼀定⾮负, 积分等于1,并且⼀定是周期性的。因此, $p(\theta)$ ⼀定满⾜下⾯三个条件:
1) $p(\theta) \ge 0$
2) $\int_{0}^{2\pi} p(\theta) \mathrm{d}\theta = 1$
3) $p(\theta + 2\pi) = p(\theta)$
考虑两个变量 $\boldsymbol{x} = (x_1 , x_2)$ 的⾼斯分布,均值为 $\boldsymbol{\mu} = (\mu_1, \mu_2)$,协⽅差矩阵为 $\boldsymbol{\Sigma} = \sigma^2 \boldsymbol{I}$ ,其中 $\boldsymbol{I}$ 是⼀个 $2\times2$ 的单位矩阵。因此有:
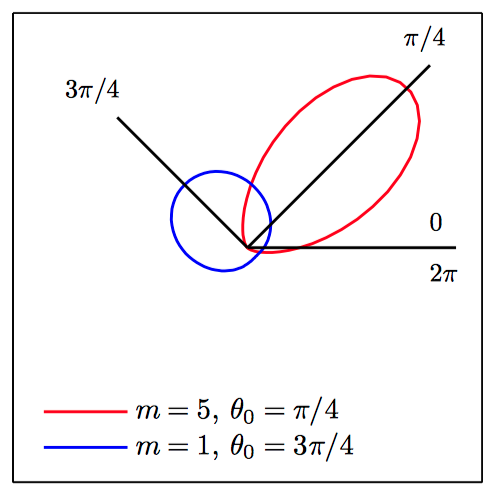
von Mises分布(环形正态分布(circular normal)):在单位圆 $r=1$上的概率分布 $p(\theta)$ 的最终表达式:
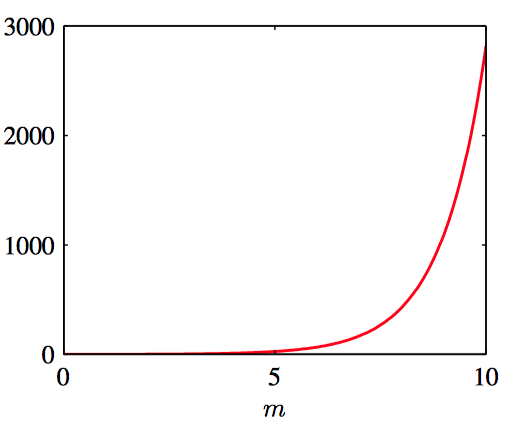
其中,参数 $\theta_0$ 对应于分布的均值,$m$ 被称为 concentration参数,类似于⾼斯分布的⽅差的倒数(精度)。归⼀化系数包含项 $I_0 (m)$,是零阶修正的第⼀类Bessel函数(Abramowitz and Stegun, 1965), 定义为:
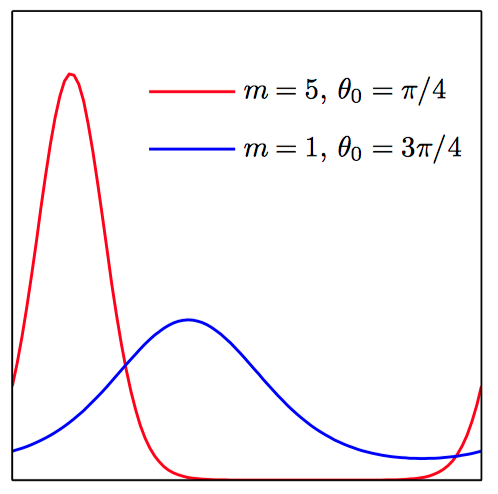
如图2.26~2.27,von Mises分布的图像。
如图2.28, Bessel函数 $I_0 (m)$ 的图像。
现在考虑 von Mises分布 的参数 $\theta_0$ 和参数 $m$ 的最⼤似然估计。对数似然函数为:
令其关于 $\theta_0$ 的导数等于零,从⽽可以得到:
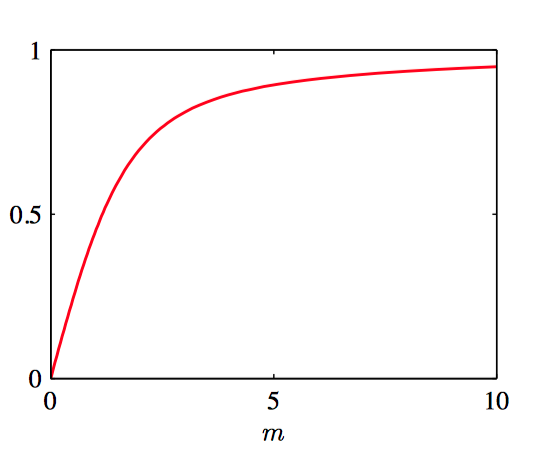
关于 $m$ 最⼤化公式(2.101),使⽤ $I_0^{\prime}(m)=I_1(m)$(Abramowitz and Stegun, 1965),从⽽可以得到:
令
可以得到:
如图2.29, 函数 $A (m)$ 的图像。
十,混合高斯模型
通过将更基本的概率分布(例如⾼斯分布)进⾏线性组合的这样的叠加⽅法,可以被形式化为概率模型,被称为混合模型(mixture distributions)(McLachlan and Basford, 1988; McLachlan and Peel, 2000)。
考虑 $K$ 个⾼斯概率密度的叠加,形式为:
这被称为混合⾼斯(mixture of Gaussians)。 每⼀个⾼斯概率密度 $\mathcal{N}(\boldsymbol{x} |\boldsymbol{\mu_{k}}, \boldsymbol{\Sigma}_{k})$ 被称为混合分布的⼀个成分(component),并且有⾃⼰的均值 $\boldsymbol{\mu_{k}}$ 和协⽅差 $\boldsymbol{\Sigma}_{k}$。参数 $\pi_{k}$ 被称为混合系数(mixing coefficients),并且满足以下条件:
1)$\sum_{k=1}^{K} \pi_{k}=1$
2)$0\le \pi_{k} \le 1$
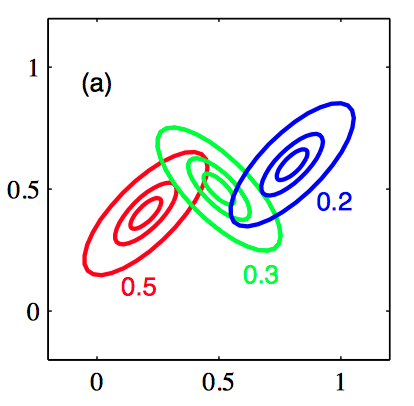
如图2.30,每个混合分量的常数概率密度轮廓线,其中三个分量分别被标记为红⾊、蓝⾊和绿⾊, 且混合系数的值在每个分量的下⽅给出。
如图2.31, 混合分布的边缘概率密度 $p(\boldsymbol{x})$ 的轮廓线。
如图2.32, 概率分布 $p(\boldsymbol{x})$ 的⼀个曲⾯图。