一,安装Kettle
1,关于简易安装Kettle
第一次接触kettle(以前只是听过罢了),摸索了几天,在mac源码安装失败,转而快速安装。在mac上安装最新版kettle并成功启动代码如下:
1 | ☁ ~ brew install kettle |
2,关于源码尝试安装kettle
1 | git clone https://github.com/pentaho/pentaho-kettle |
- 设置
setting.xml
将 setting.xml 参见: settings.xml 在你的Maven启动目录/.m2中。
1 | ☁ pentaho-kettle [master] ⚡ ll /Users/zhangbocheng/.m2 |
- 安装
1 | ☁ pentaho-kettle [master] mvn clean install >> /Users/zhangbocheng/Desktop/kettle.log |
- 关于
error.log
未设置 setting.xml报错问题
1 | ..................................... |
设置 setting.xml后,就一直处在等待中。
二,实验案例
关于课程实验,第一次需要亲手搭建Kettle,这算是一次比较有意思的工程实践机会,花最少的时间来认识认识比较流行而且强大的ETL工具之一—Kettle。
1,关于实验题目
任务描述:用kettle完成下列实验,结果存储到MySQL(或者CSV)。已知Excel文件,包含列(姓名,年龄,身份证号码,性别,挂号日期时间,门诊号),数据若干。
生成数据1,包含列(日,性别,儿童/青年/中年/老年,人次),其中儿童/青年/中年/老年的年龄段自己定义;
生成数据2,包含列(省份,hour,人次)
第一次接触kettle,力求简单,仅考虑输入输出均为Excel,首先按照题目要求捏造一批数据,如下图所示:
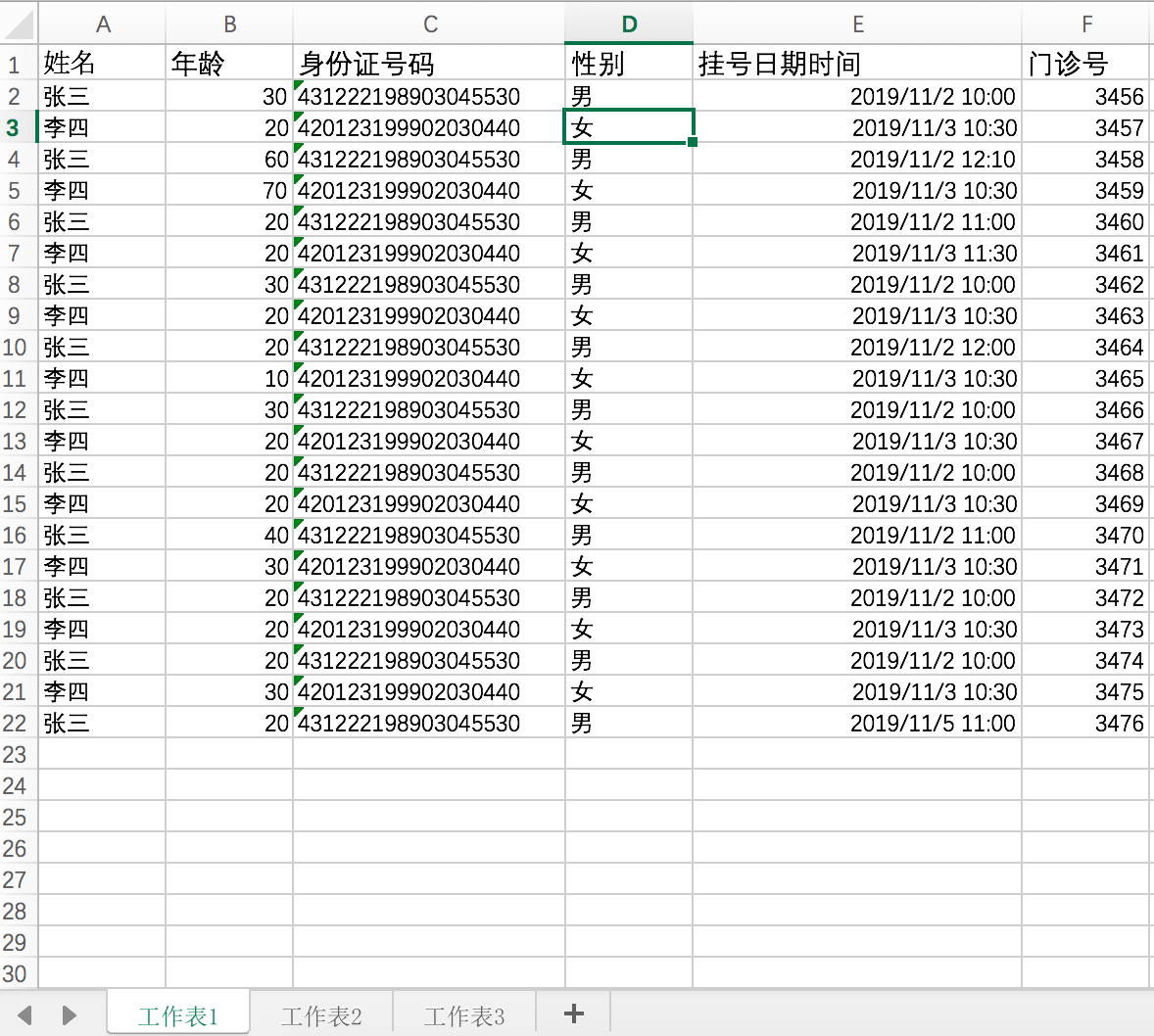
Excel字段说明:
1 | 姓名:字符串 |
进入安装目录/usr/local/Cellar/kettle/8.2.0.0-342/libexec启动kettle:
根据实验要求,其实所涉及的问题仅仅是输入和输出,转换(分组统计)。创建任务之初,有必要先百度or Google看看kettle的输入输出是如何实现的?
2,实例预热
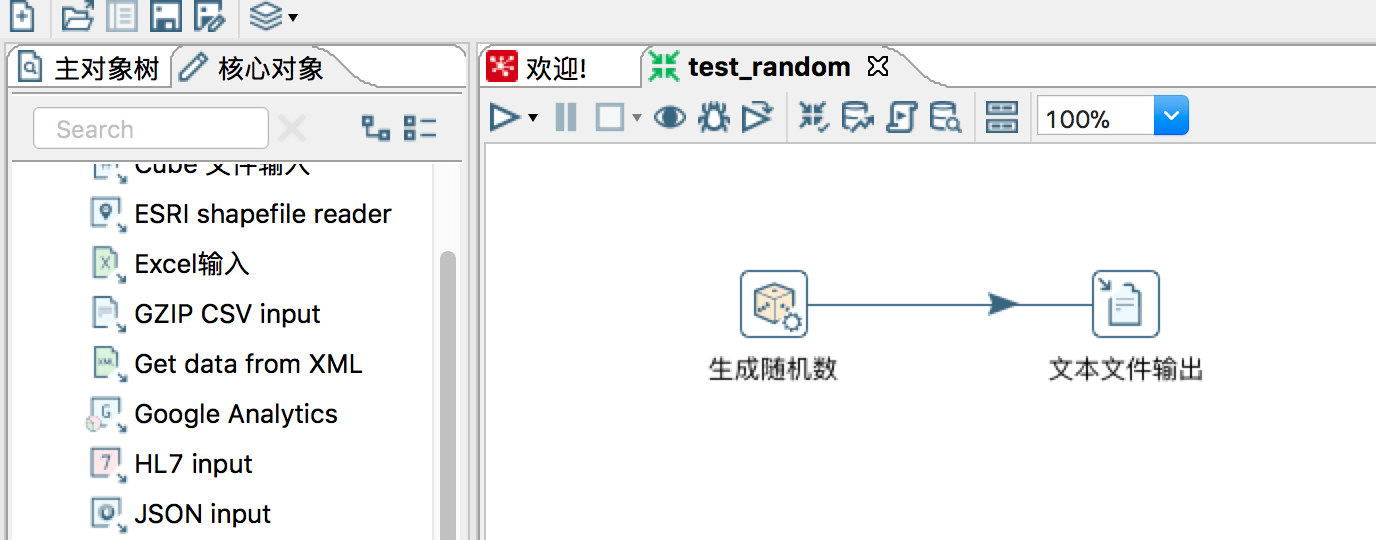
最容易实现的简单案例就是生成随机数,并存储到txt文件。
1)新建一个转换保存为test_random(后缀为.ktr)通过拖拽插件方式,在核心对象->输入和输出分别拖拽“生成随机数”和“文本文件输出”两个按钮,然后点击“生成随机数”并按下sheft键,用鼠标指向“文本文件输出”,以生成剪头,表示数据流向。如下图:
2)编辑输入流,即“生成随机数”按钮,如图所示:
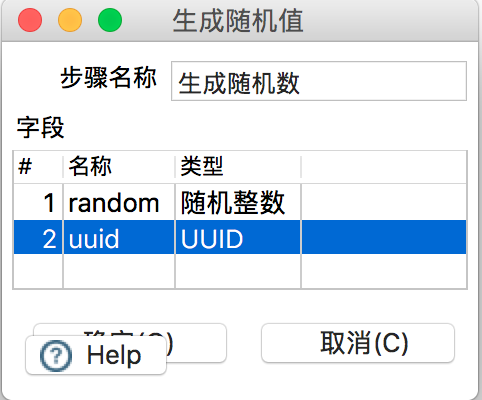
关于支持的随机数据类型有:
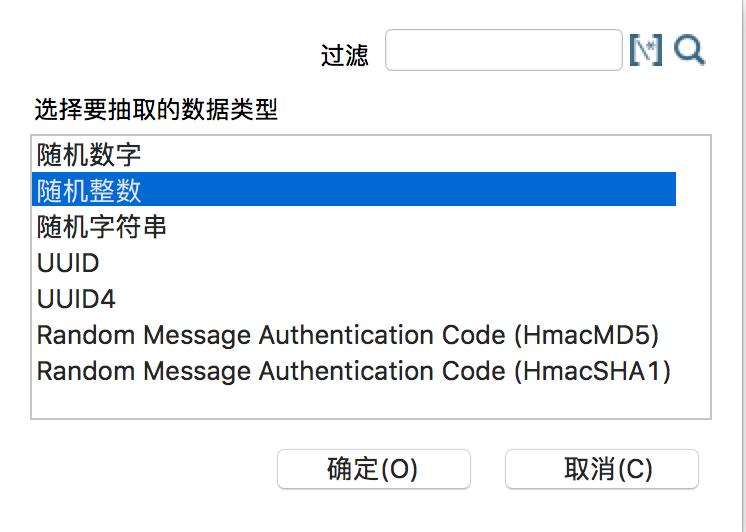
3)然后编辑输出流,即“文本文件输出”按钮,如图所示:
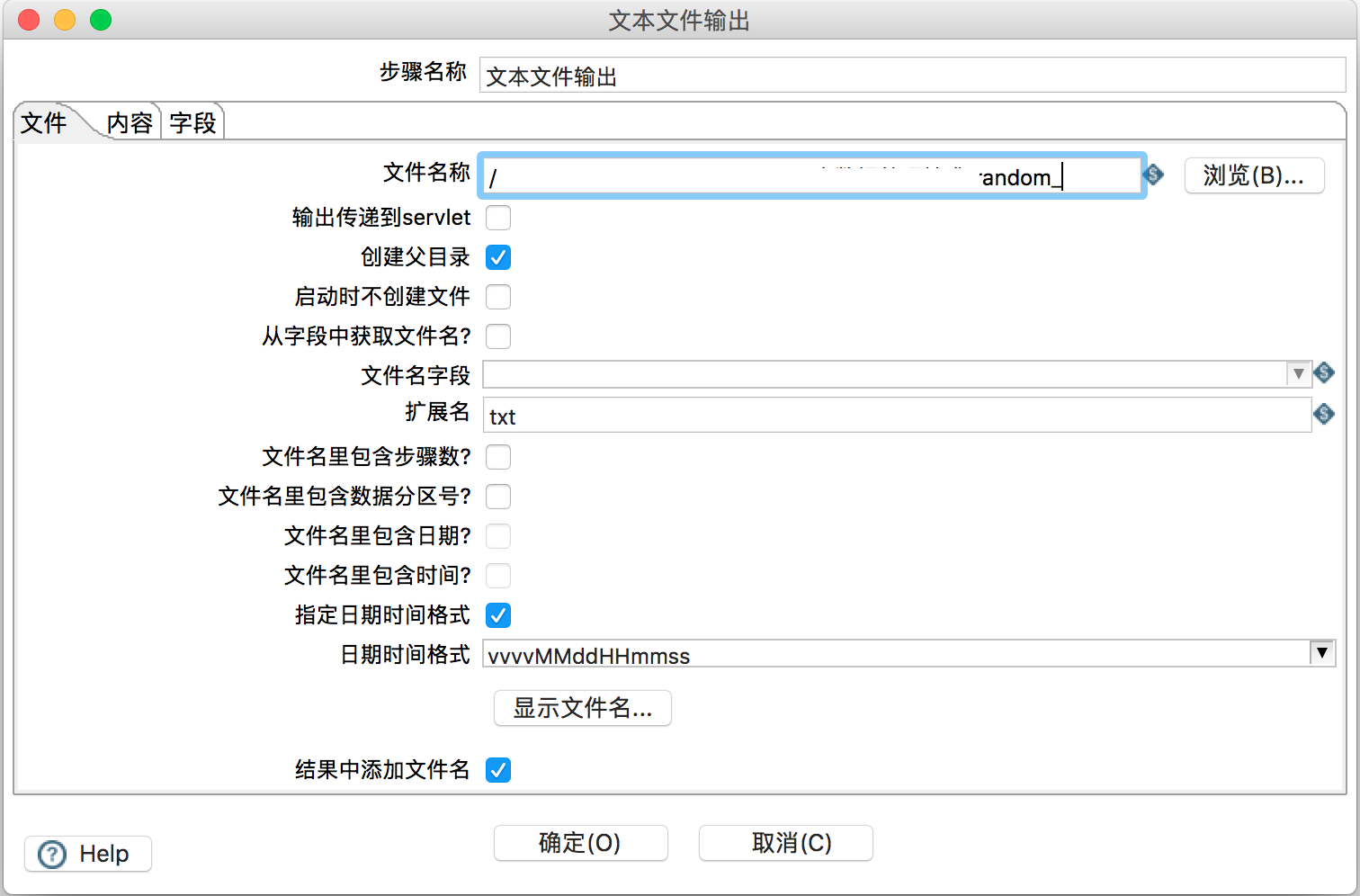
输出文件名支持预览模式,即点击图中“显示文件名…”按钮:
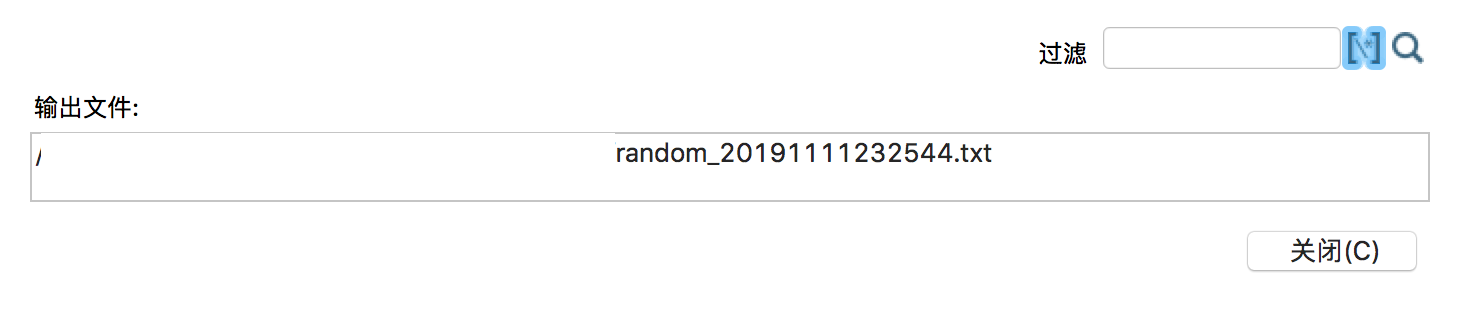
4)最后执行,看看结果。
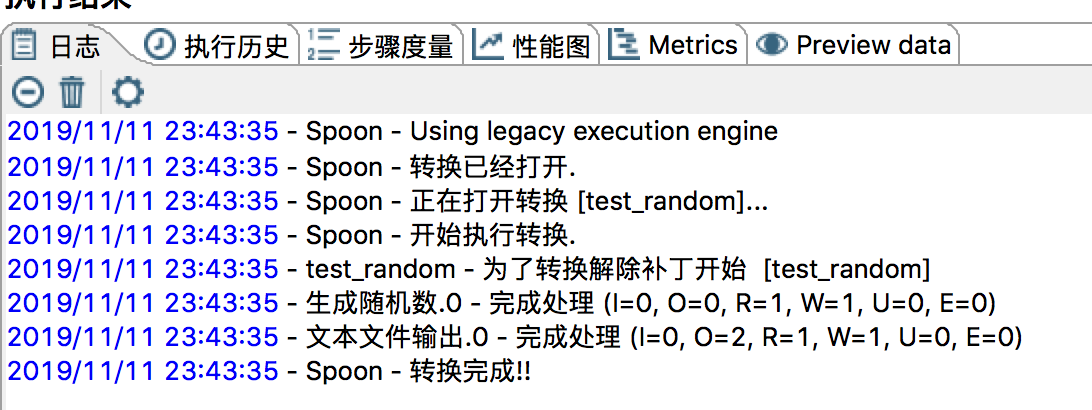
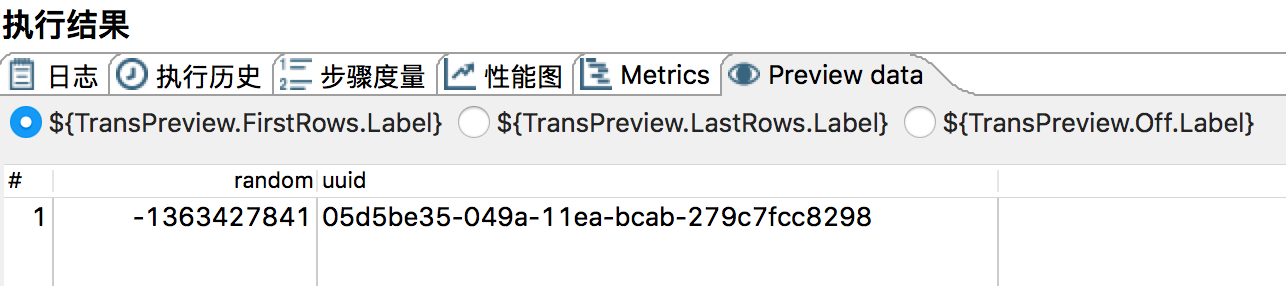

3,实验步骤
通过上述简单实验,我们知道了输入输出流的基本操作,下面开始进入正题。
1)将上述实验中的输入输出全部改为Excel。进行相关配置说明如下:
Excel输入:
在文件选项下,表格类型根据实际进行适配(xls or xlsx),在文件或目录后,点击“浏览”选择自己的源数据文件,然后点击“添加”;
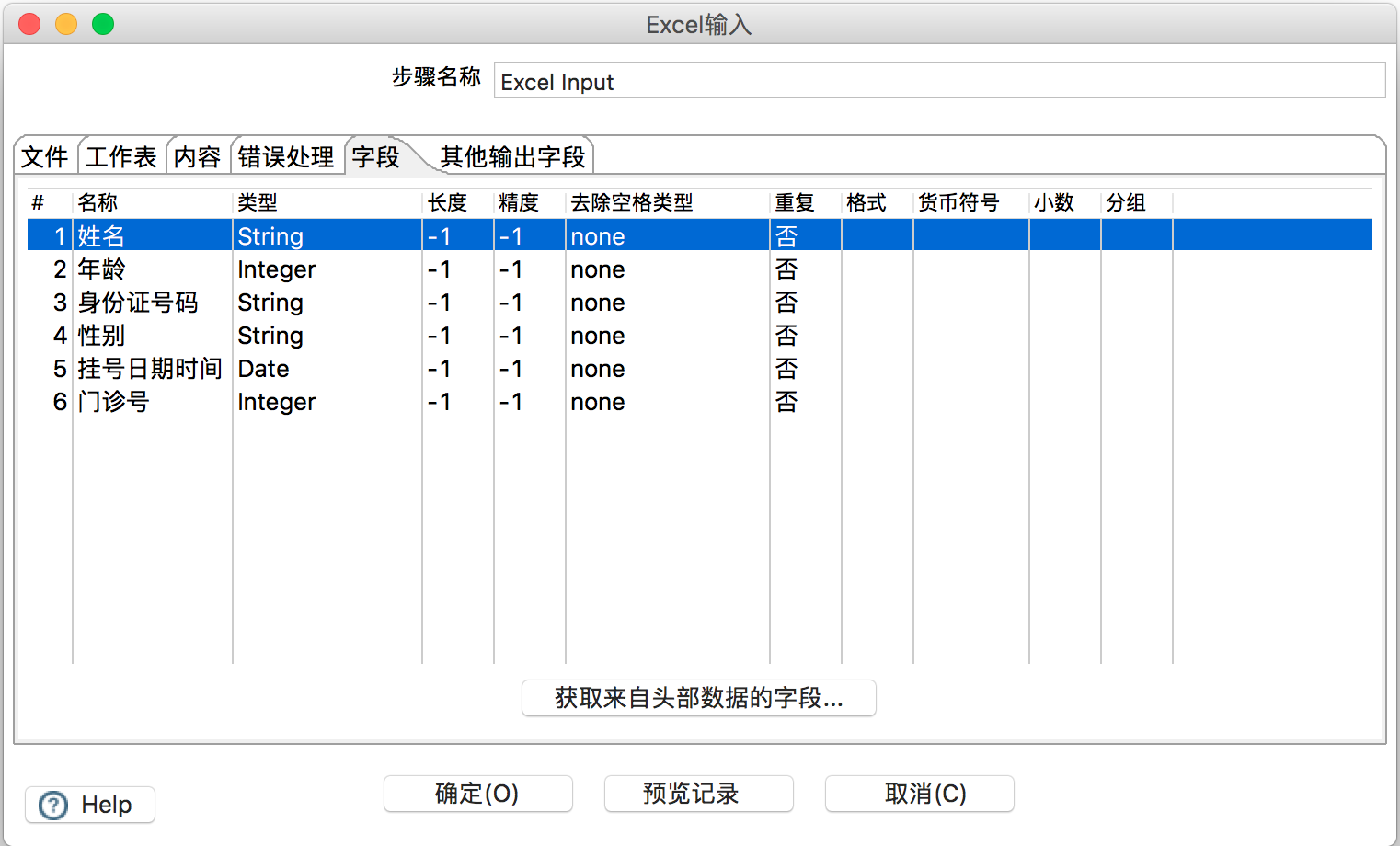
在工作表选项下,点击“获取工作表名称…”添加工作表,即Excel中的sheet;
在字段选项下,点击“获取来自头部数据的字段…”自动获取字段,由于原Excel中整型数据转入会变成浮点型,所以需要进行更改,如图所示:
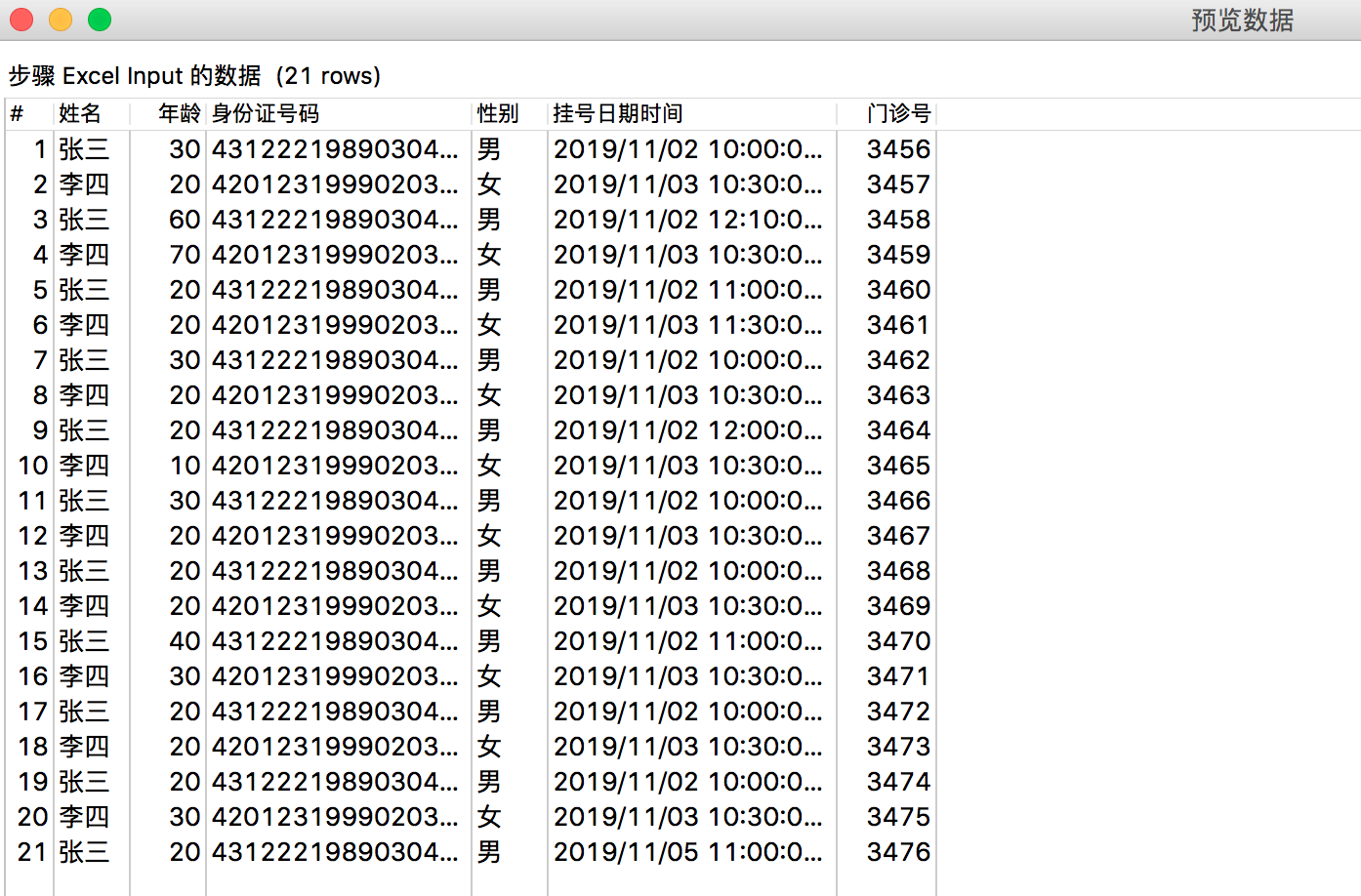
最后可以进行预览。
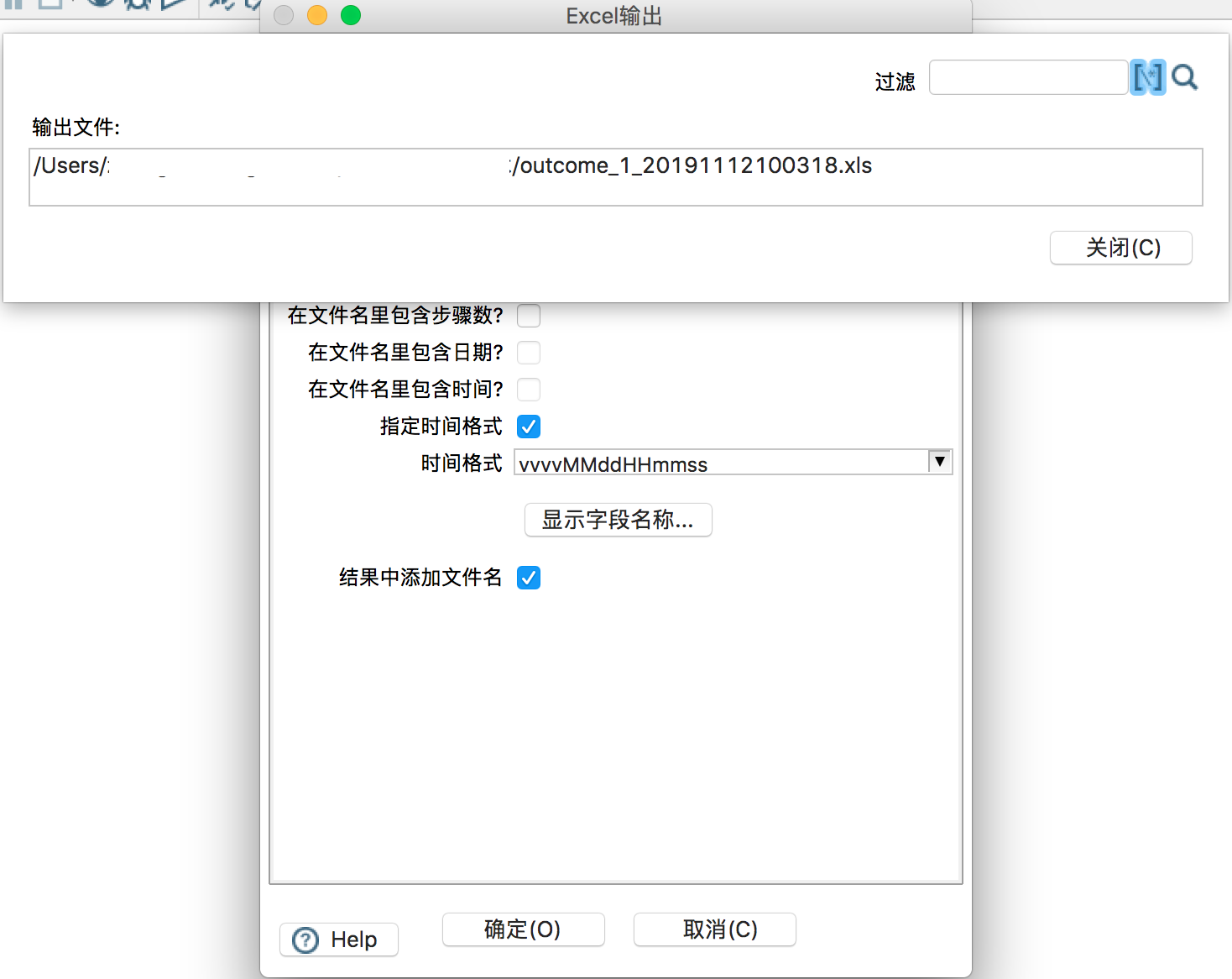
Excel输出:只需要配置输出文件名即可,其他均为默认。
2)接下来需要处理的就行核心步骤,即转换。首先针对生成数据1进行分析,由于kettle中分组需要首先进行排序,从而需要处理的点有:
(1)将挂号日期时间截取到日;
(2)对年龄按照一定标准进行转换(自己定义);
(3)按照待分组的字段进行排序;
(4) 进行分组统计。
按照上述思路,在“转换”和“统计”核心对象中,分别找到对应组件,完成基本数据流节点配置,如图所示:

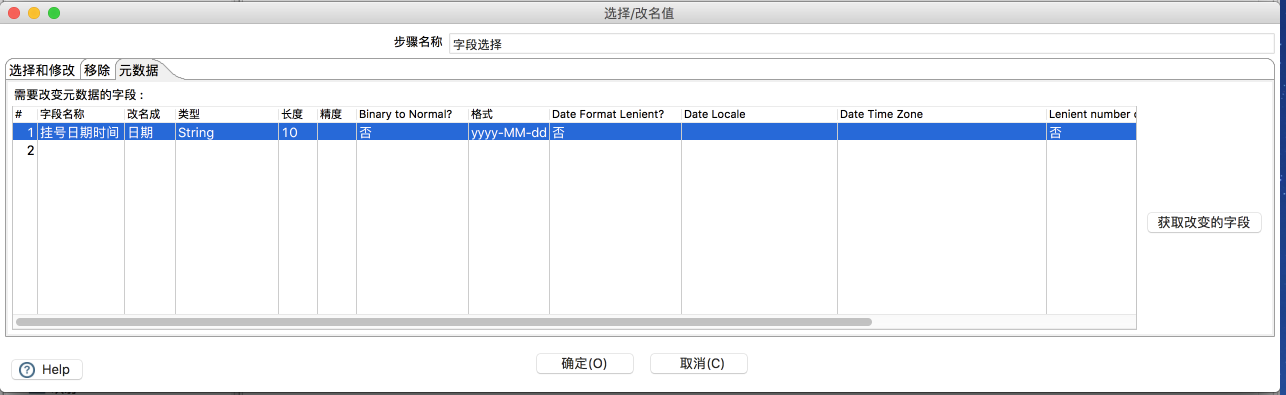
在“字段选择”组件中,对时间进行处理。在元数据选项中,需要对Date进行转换成String,格式设置为yyyy-MM-dd,同时可以对字段进行更名操作。另外还可以对字段进行选择,修改,移除。如图所示:
注意,这里如果不将时间设置为String,进行一个小实验可以可以发现,最后存储的依然是带时间的日期,本次实验过程中在这个坎纠结了,错误地以为是kettle不支持多关键字(两个以上)排序,如下图所示:
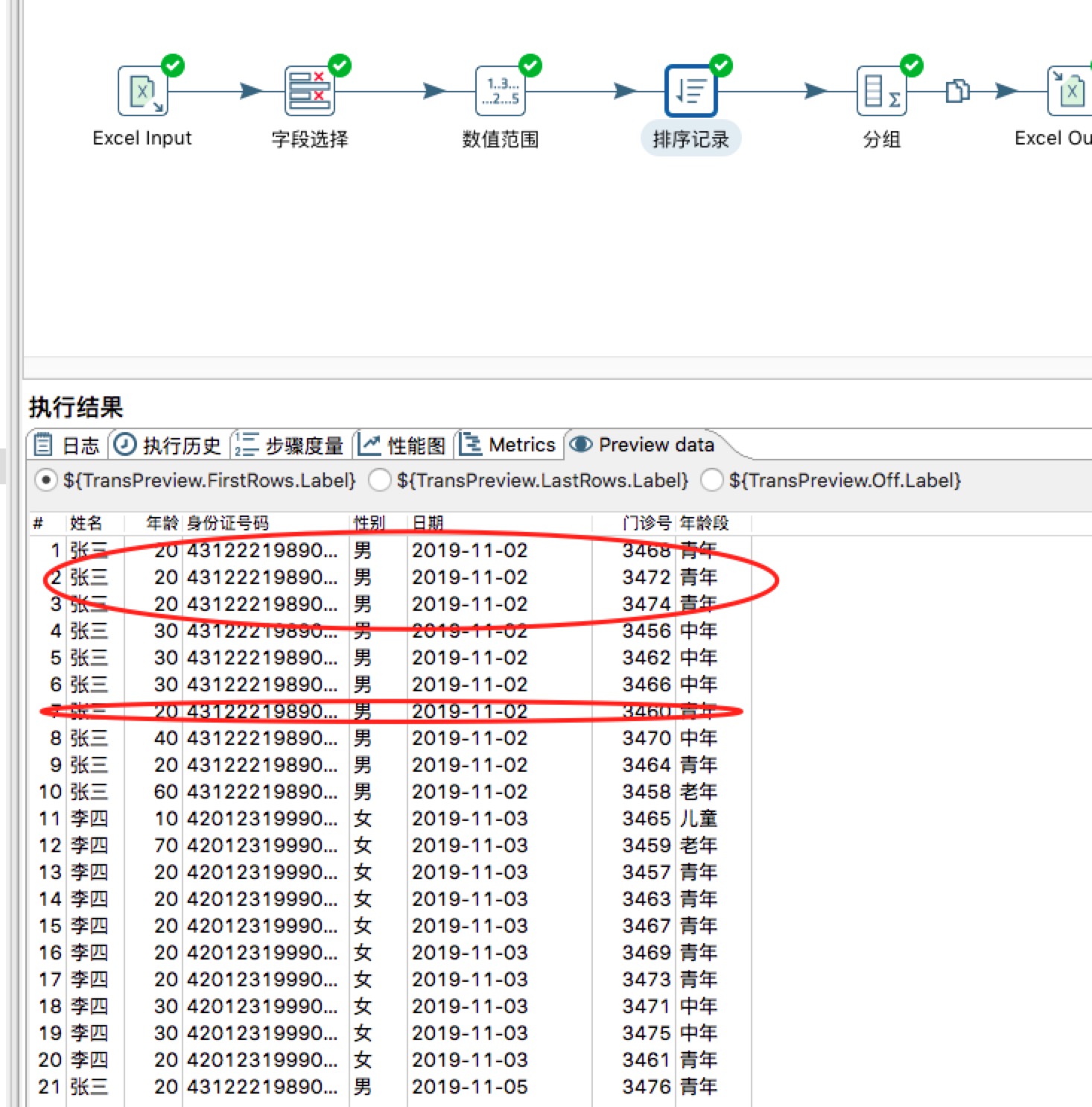
经过与各位大佬沟通确认,kettle是不可能不支持对多关键的排序的,对此深信不疑,那么问题就从kettle本身存在的可能bug消失了,对一个小白而言,不熟悉kettle本身应遵守的规则,这是致命的,只能对怀疑的其他种种可能进行逐一实验了。期间怀疑过待排序关键字的顺序问题,测试发现都不是问题的根本原因,整个过程下来只有对日期做过预处理,而且从错误中发现,引起错排的唯一合理解释就是日期按照预处理之前的原始数据的日期时间型排序的。单独对日期设计实验,如果对预处理生效,那么输出也是预期结果。
- 验证日期实验
输入流,如图所示:
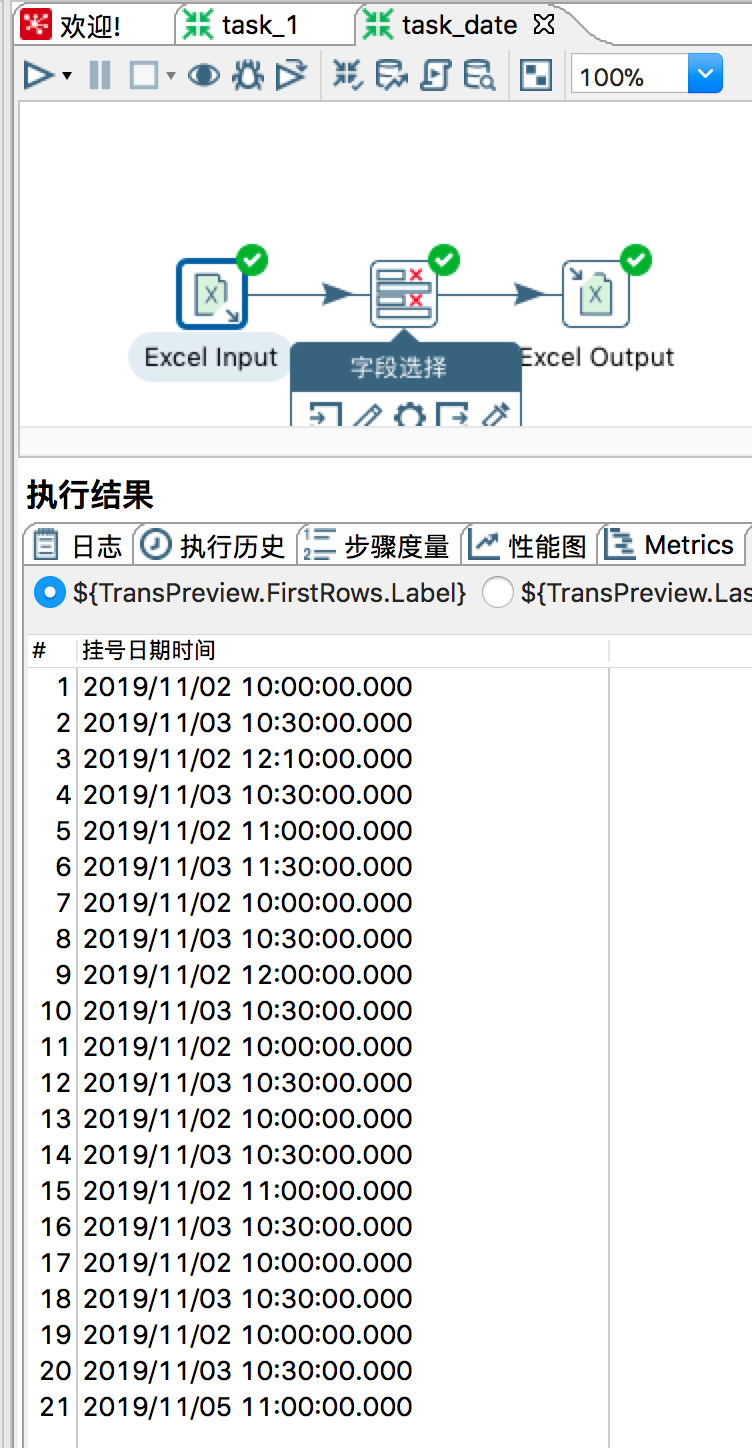
假设日期类型不改成String,如图所示:

输出流,结果预览,如图所示:
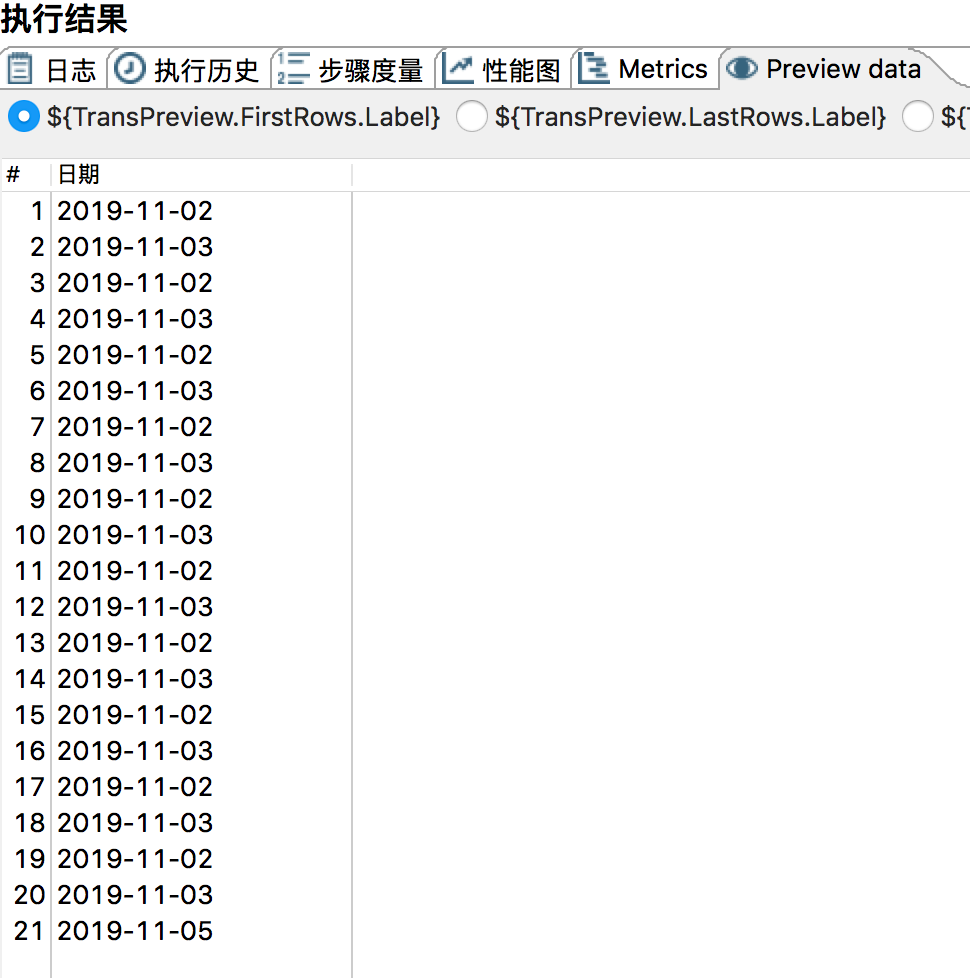
输出流,Excel输出,如图所示:
验证实验室结果发现,预览数据并没有存储到输出Excel中去,然后尝试转换为String,输出便一致了。再次验证,kettle对日期类数据处理有待提高。
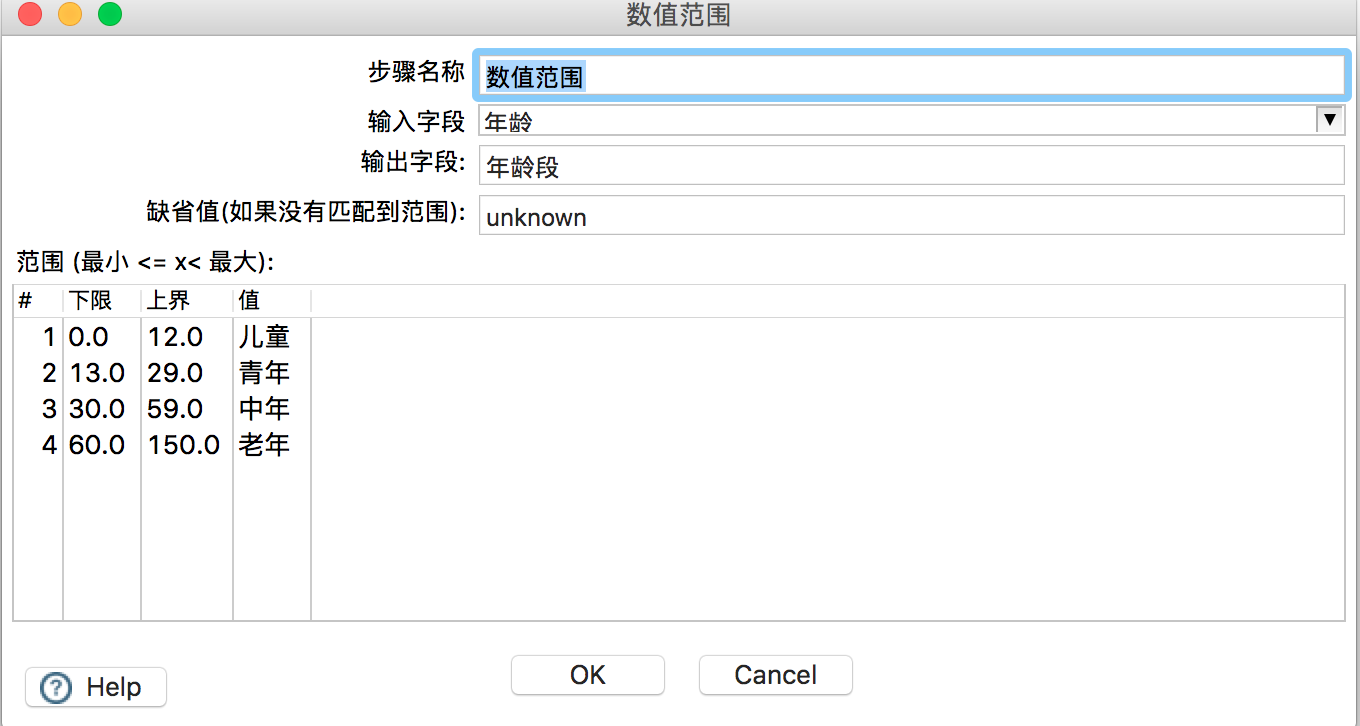
在“数值范围”组件中,对年龄进行处理,划分标准自己定义(如下定义可能存在瑕疵)如图所示。
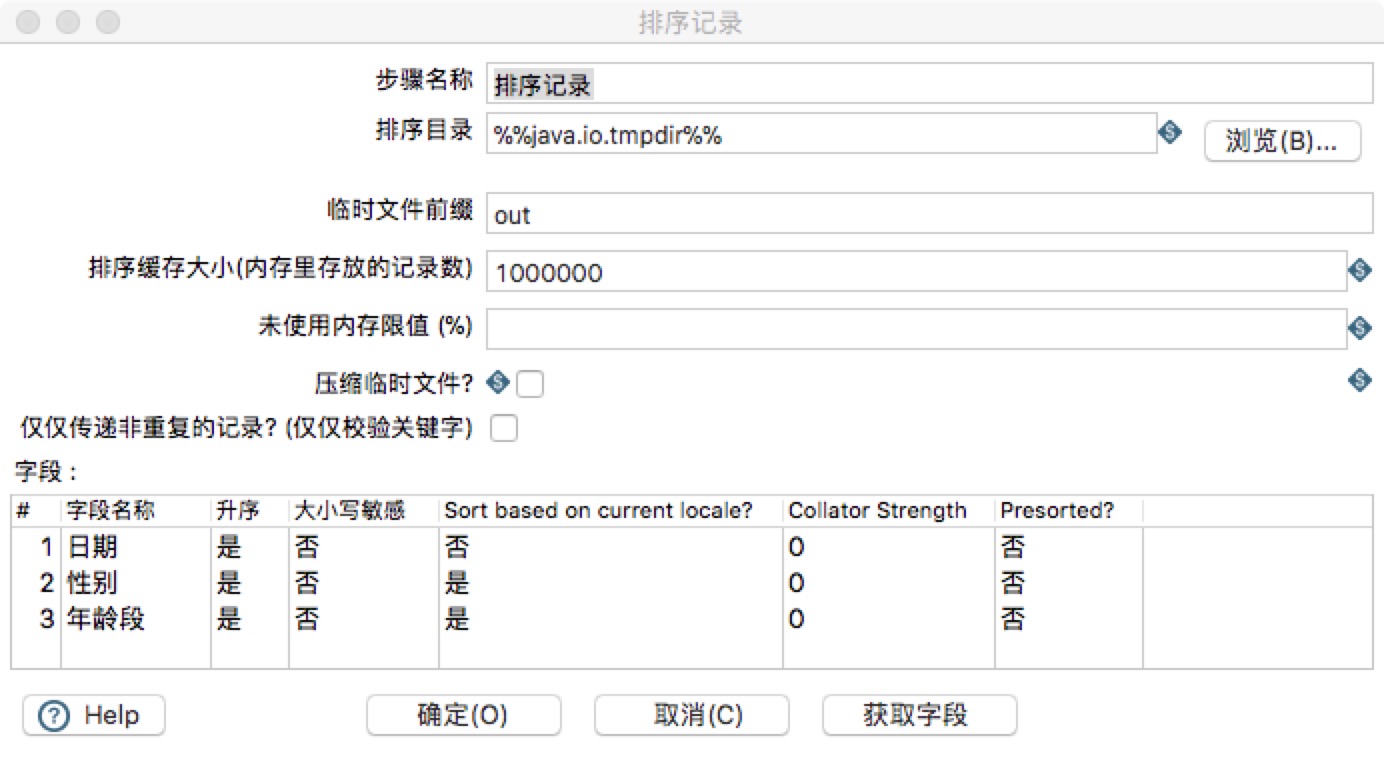
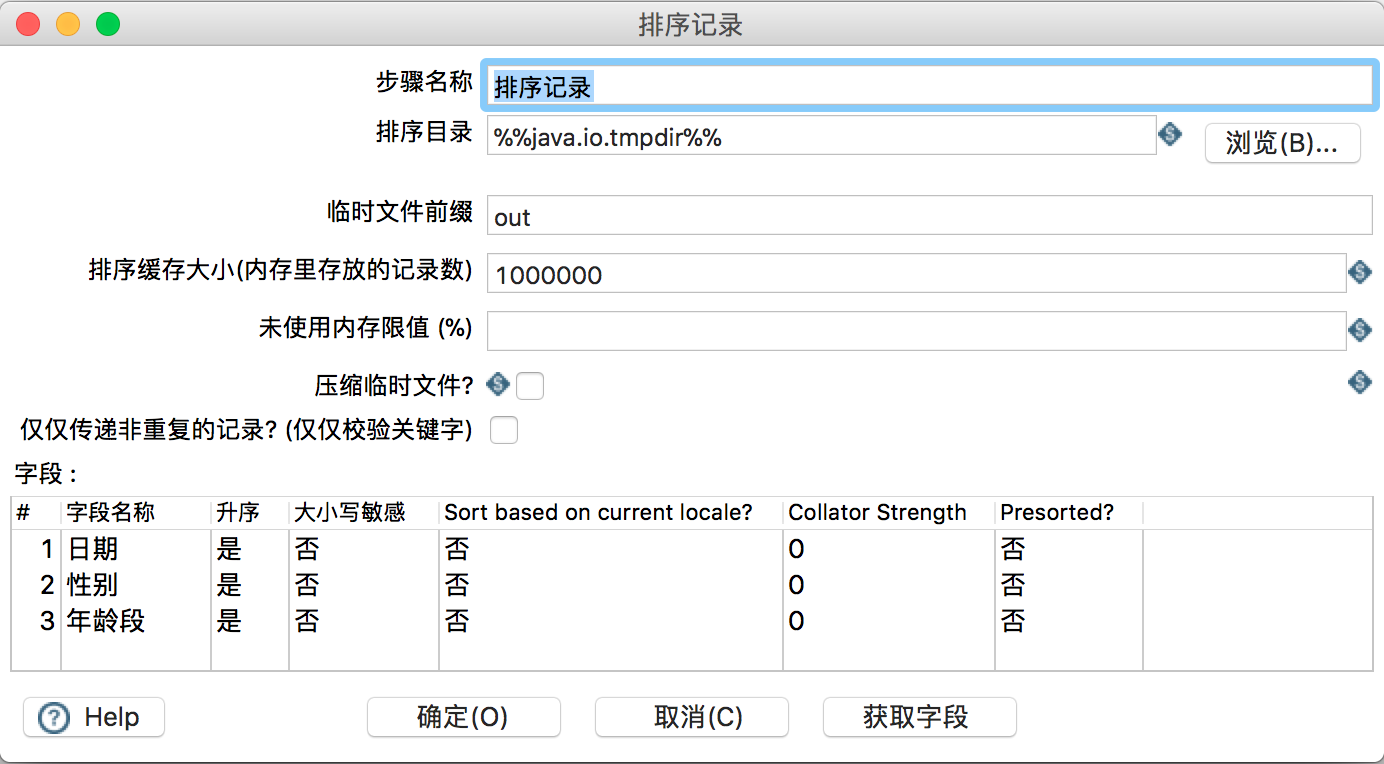
在“排序记录”组件中,按照生成数据要求,需要对日期,性别,年龄段进行来袭,如图所示。
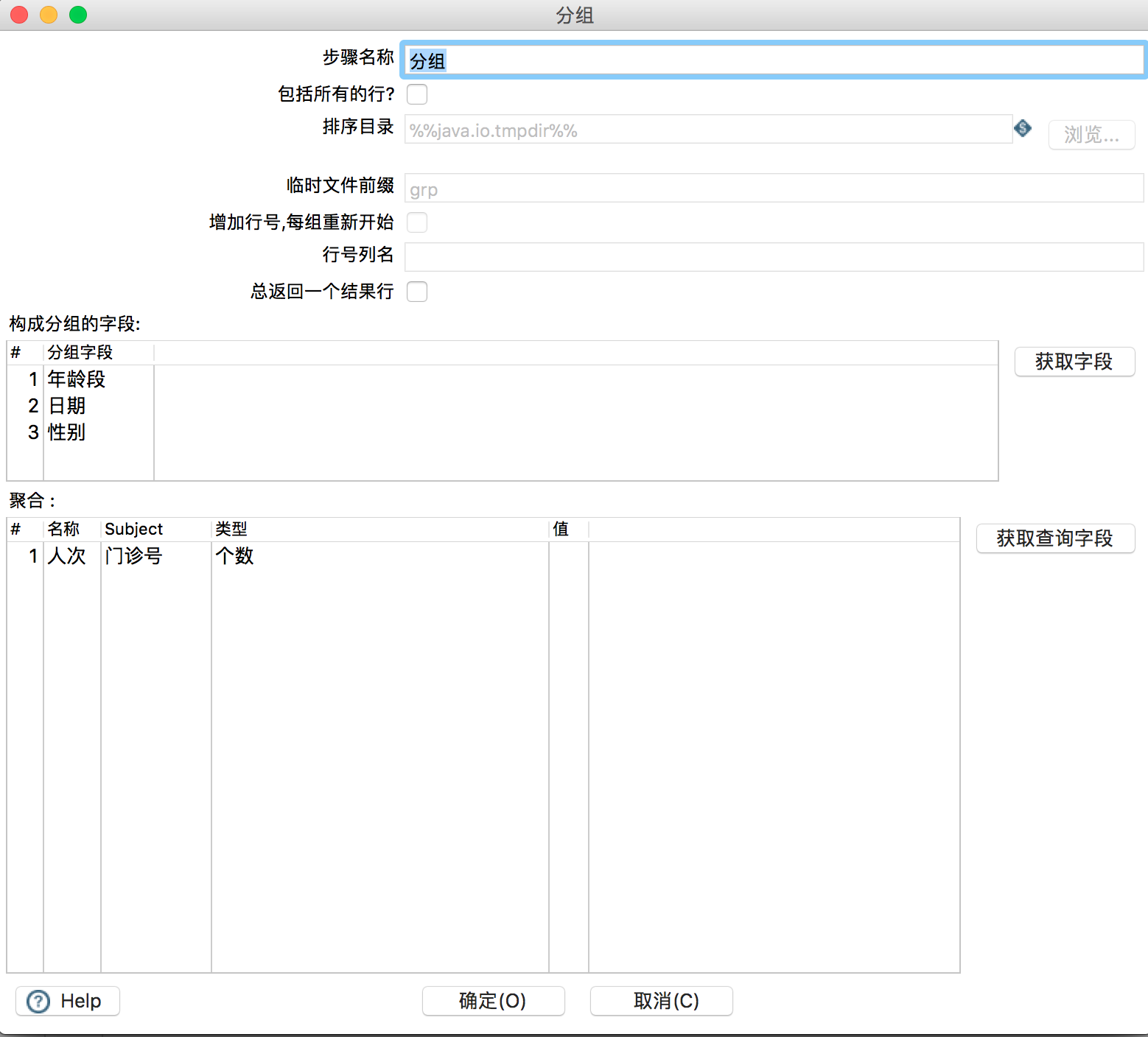
在“分组”组件中,进行分组统计,如图所示。
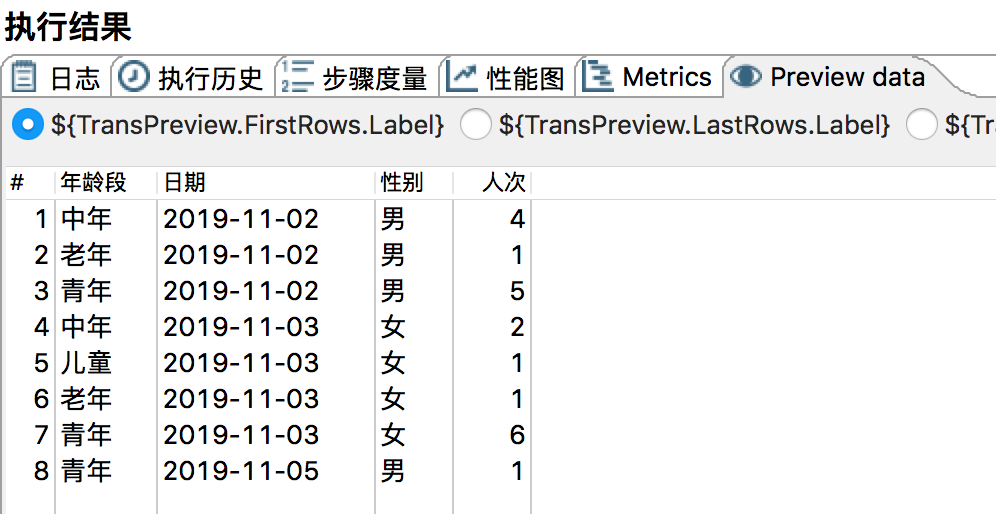
3)执行,结果如图所示。
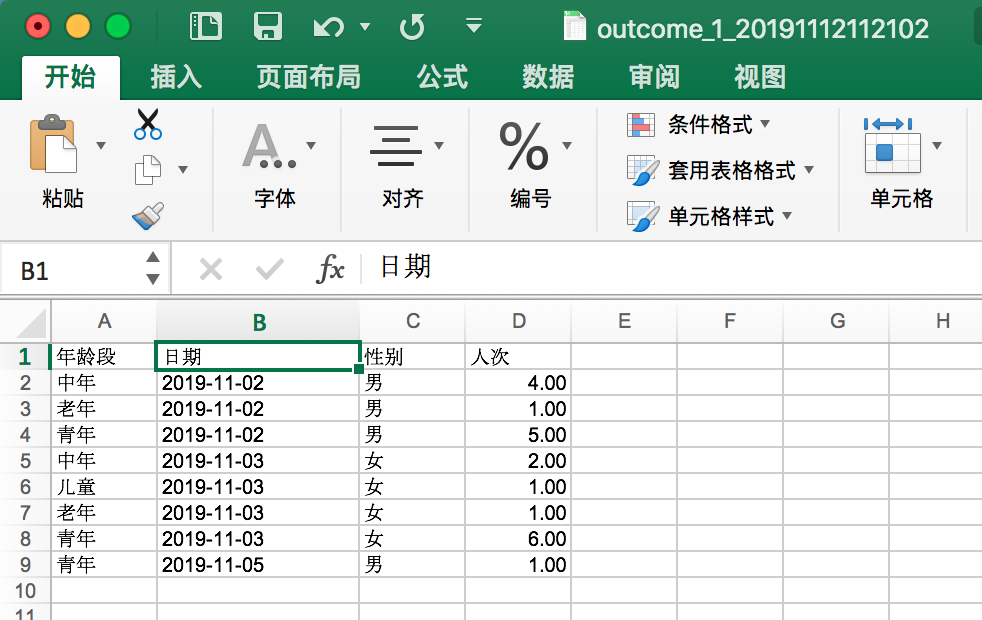 ß
ß
4,实验二简要说明
针对生成数据2进行分析,需要处理的点有:
(1)将挂号日期时间设置
String,由于不能直接从预设格式中提取日,需要采取字符串截取;(2)对日期和身份证进行字符串截取,分别提取日和省份代码(身份证前两位);
(3)按照待分组的字段进行排序;
(4)对省份和时间段进行值映射;
(4) 进行分组统计。
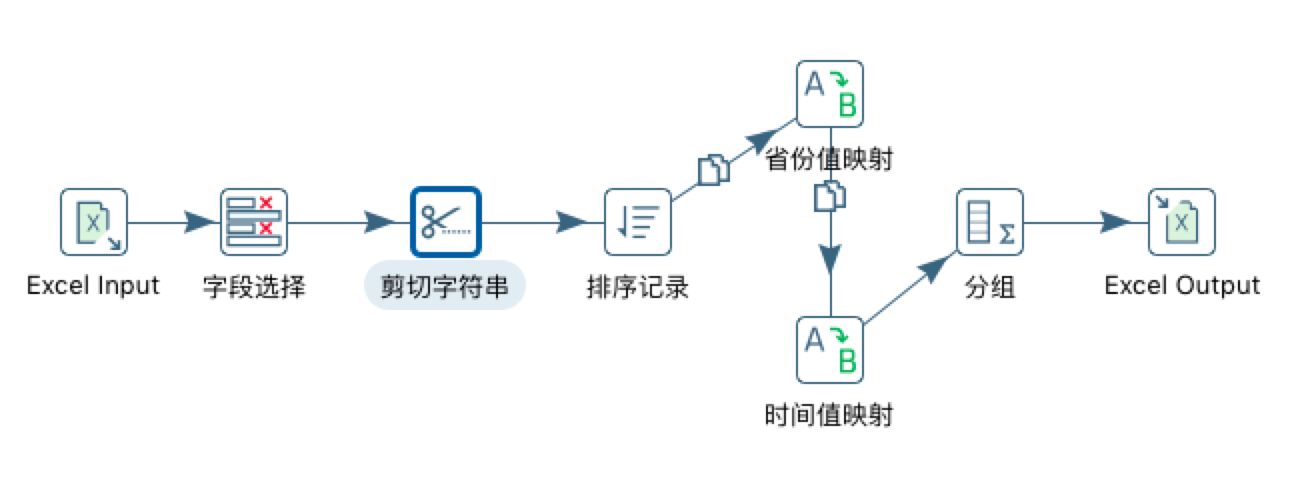
整体设计数据流图,如图所示:
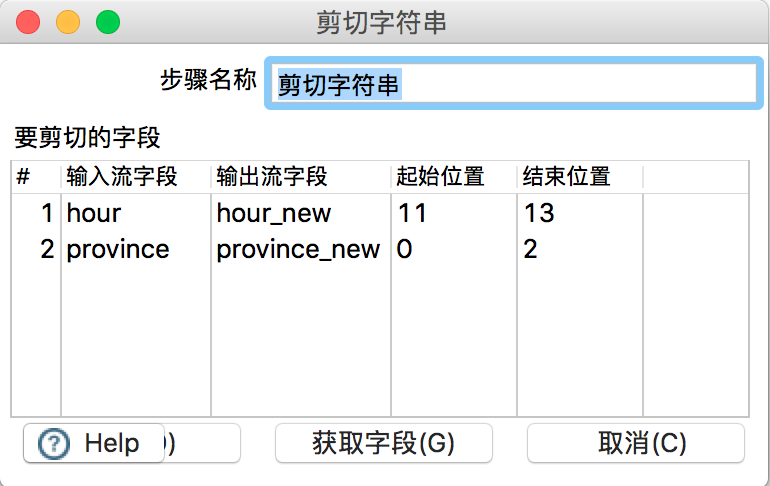
在“剪切字符串”组件,设置如下:
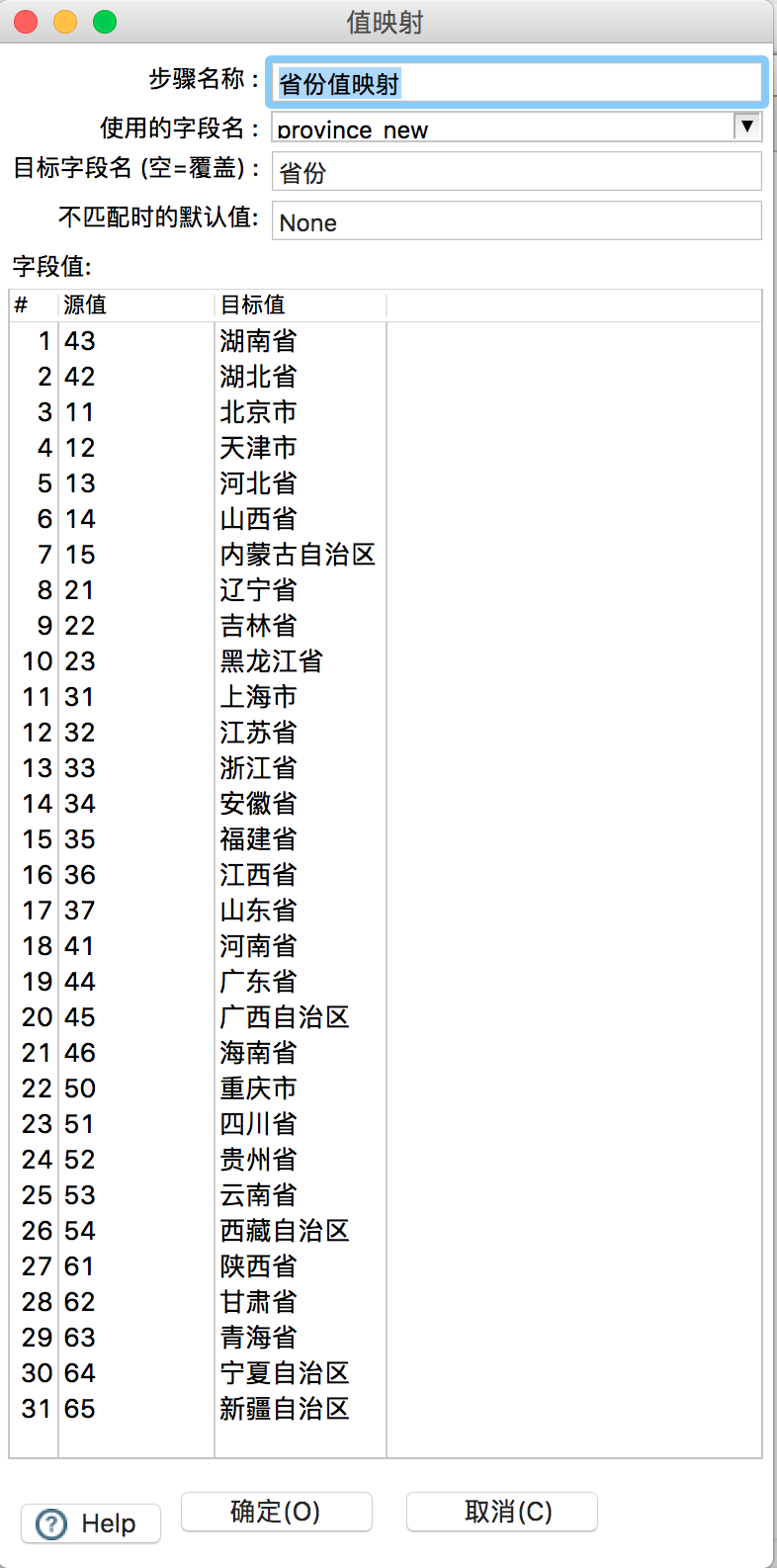
在“省份值映射”和“时间值映射”组件中,分别设置如下:

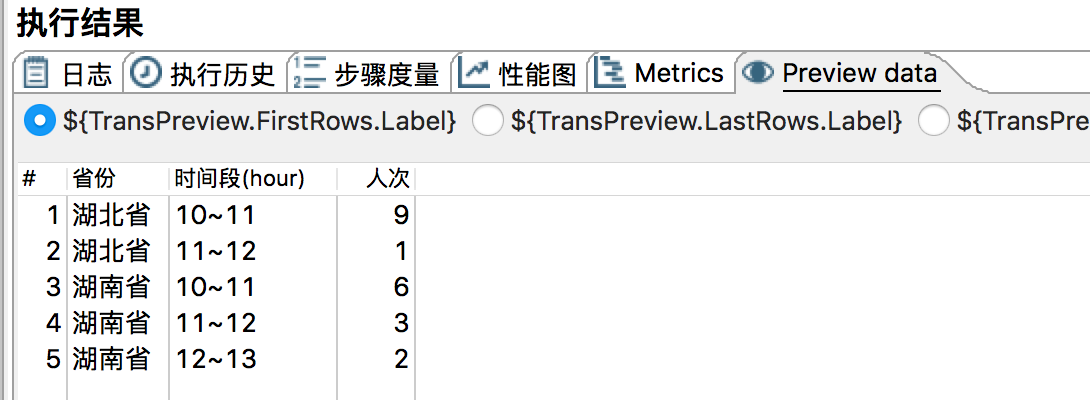
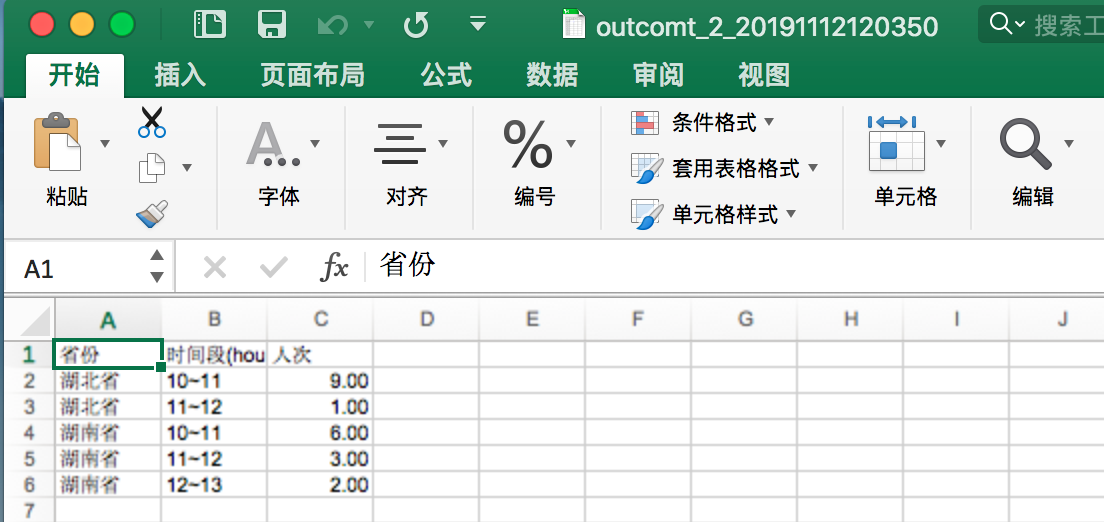
运行结果,如图所示:
三,总结
通过本次实验,初步认识了一下强大的ETL工具之kettle,要想获取更多知识就得更多实验,从错误中反思学到的远比从成功中收获更多。作为工具,只有多多实验才能更好的掌握好它,印证了那句经典—“实践出真知”。

