本系列为《Hadoop大数据处理基础与实践》的读书笔记。
一,准备环境
PC基本配置如下:
1 | 处理器:Intel(R) Core(TM) i5-3230M CPU @ 2.6GHz 2.60GHz |

- 初始化四台
Ubuntu-14.04_x64虚拟机,配置如下:
1 | 内存:2GB |

- 修改系统时区
1 | ~ sudo timedatectl set-timezone "Asia/Shanghai" |
- 为方便使用建议如下配置:
安装
oh-my-zsh插件;设置
VIM行号;安装
SSH插件服务;安装
vsftpd插件服务并加以配置,方便文件上传下载;在
PC上安装XSHELL客户端;在
PC上安装FTP客户端。
- 需要的软件:
1 | apache-tomcat-7.0.52.tar.gz 链接:http://pan.baidu.com/s/1nvjjd6T 密码:6ft0(暂不需要) |
- 在虚拟机做如下步骤:创建目录,存储工具包
/home/zhangbocheng,并利用FTP上传相关软件包。


二,安装单机环境
- 安装
Java1.7.0
1 | ~ mkdir java |

- 安装
Hadoop2.2.0
1 | ➜ ~ tar -xf /home/zhangbocheng/hadoop-2.2.0-x64.tar.gz |
- 配置环境
1 | ➜ ~ vi .zshrc |

- 修改
Hadoop2.2.0配置文件
1 | # 检查并修改以下三个文件中JAVA_HOME的值 |
- 修改主机名称(千万不要含有下划线
_)
1 | ➜ ~ sudo hostname master # 只对当前状态生效 |
- 关闭防火墙
1 | ➜ ~ service ufw status |
三,克隆VM
通过 VMware Workstation工具,关闭当前虚拟机,对其克隆三台虚拟机作为从机使用。
克隆方法选择“创建完整克隆(F)”,如图所示:

四,搭建集群
- 修改三台从机
slave的host,并再重启使之生效。
1 | ➜ ~ sudo vi /etc/hostname |
- 对所有集群中的服务器进行检查,关闭防火墙并禁止掉。
1 | ➜ ~ sudo service ufw status |
- 对所有集群中的服务器绑定
hostname与IP
1 | ➜ ~ sudo vi /etc/hosts |
- 对所有集群中的服务器创建
SSH密钥,完成相关验证,注意保留原有的其他密钥,以备他用
1 | ➜ .ssh mv id_rsa id_rsa_git |
- 配置各个节点之间免密登录
1 | # 将slave_1节点rsa通过ssh-copy-id分别复制到master,slave_2,slave_3 |
五,Hadoop启动与测试
格式化文件系统
1
2
3
4
5
6
7
8
9
10➜ ~ hdfs namenode -format
19/11/13 21:57:48 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/192.168.71.128
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.2.0
.........
19/11/13 21:57:55 INFO util.ExitUtil: Exiting with status 0 # 表示成功
.........启动
HDFS1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20zhangbc@master:~$ start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /home/zhangbc/hadoop2.2.0/logs/hadoop-zhangbc-namenode-master.out
slave_1: starting datanode, logging to /home/zhangbc/hadoop2.2.0/logs/hadoop-zhangbc-datanode-slave_1.out
slave_3: starting datanode, logging to /home/zhangbc/hadoop2.2.0/logs/hadoop-zhangbc-datanode-slave_3.out
slave_2: starting datanode, logging to /home/zhangbc/hadoop2.2.0/logs/hadoop-zhangbc-datanode-slave_2.out
zhangbc@master:~$ jps
6524 Jps
5771 NameNode
zhangbc@slave_1:~$ jps
4919 Jps
4818 DataNode
zhangbc@slave_2:~$ jps
4919 Jps
4801 DataNode
zhangbc@slave_3:~$ jps
4705 DataNode
4800 Jps
WEB验证:http://192.168.71.128:50070

- 启动
Yarn
1 | zhangbc@master:~$ start-yarn.sh |
WEB验证:http://192.168.71.128:8088
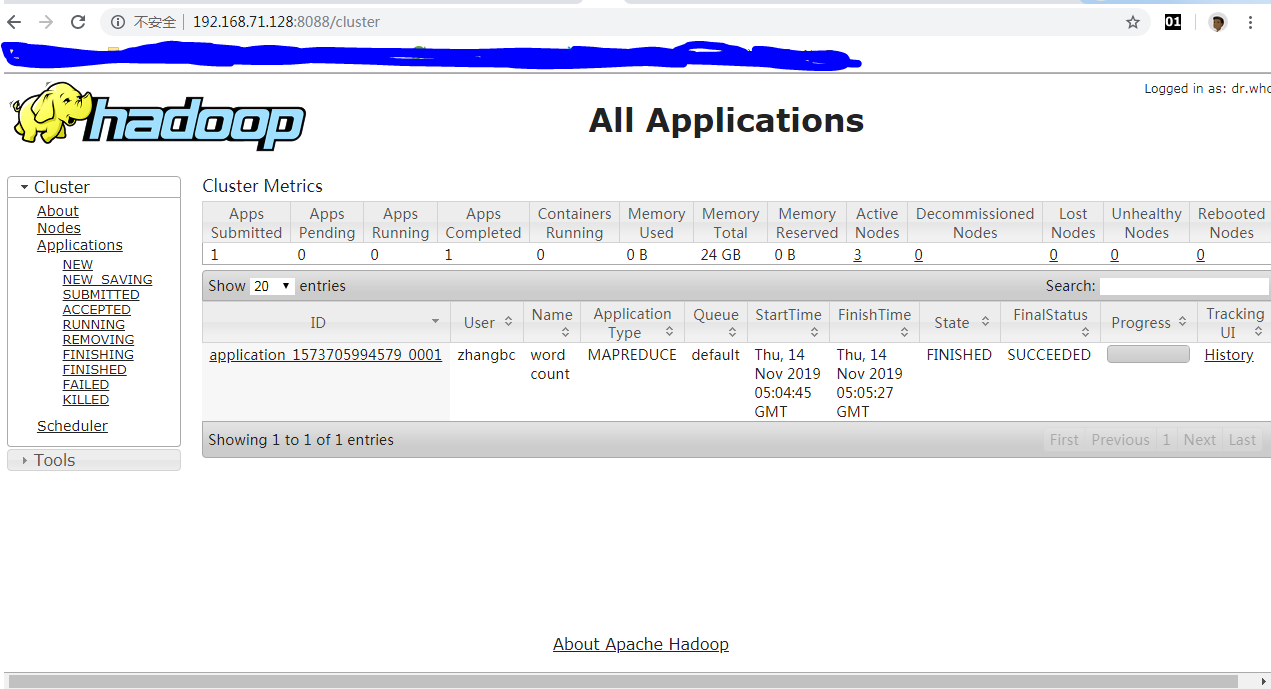
- 管理
JobHistory Server
1 | zhangbc@master:~$ mr-jobhistory-daemon.sh start historyserver |
WEB验证:http://192.168.71.128:19888
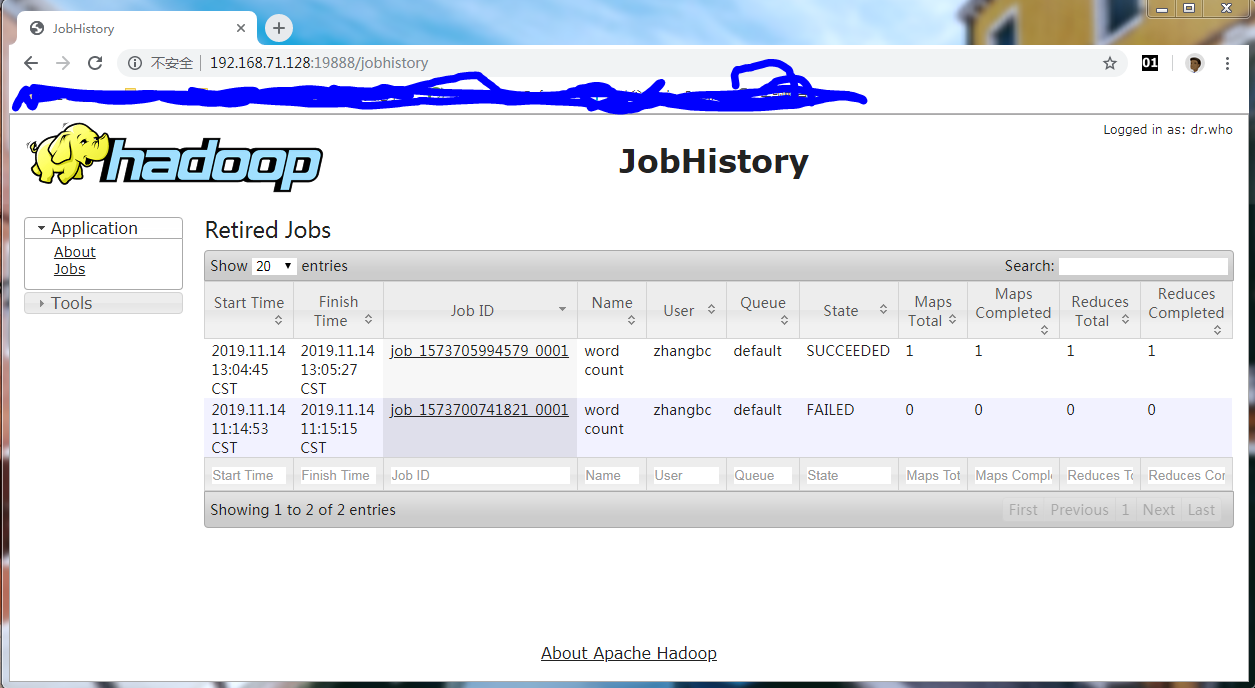
- 集群验证
1 | # 创建目录 |
六,安装过程中遇到的问题及其解决方案
- 问题1:上传文件报错
1 | zhangbc@master:~$ hdfs dfs -put hadoop2.2.0/etc/hadoop/core-site.xml /data/wordcount |
主要原因是重新格式化文件系统,导致master节点下的hadoop2.2.0/hdfs/name/current/VERSION中的clusterID和Slave节点下的hadoop2.2.0/hdfs/data/current/VERSION中的clusterID不一致。在浏览器输入master:50070可以发现Live Nodes为0。
解决方案是修改master节点下的clusterID使之与Slave节点下的clusterID一致,然后重启服务即可。
- 问题2:执行
JAR报错问题
1 | Container launch failed for container_1573700741821_0001_01_000007 : java.lang.IllegalArgumentException: Does not contain a valid host:port authority: slave_1:33775 |
主要原因:Hadoop nodemanager结点主机名不能带下划线_。
解决方案:修改主机名称。
- 问题3:绑定主机名引起的问题:
sudo: unable to resolve host master
解决方案如下:
1 | ➜ ~ sudo vi /etc/hosts |
通过本次实验,对集群概念有个基本的认识,在搭建过程中遇到问题不算太多,主要是对局域网组建缺乏认识深度,本集群环境可以进一步扩展,如动态增减节点,借助Zookeeper技术加以融合等在企业中是比较常见的做法。

