标题:【Leetcode刷题】28. 实现 strStr()
题目描述
实现
strStr()函数。给定一个
haystack字符串和一个needle字符串,在haystack字符串中找出needle字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。
思路分析
方法一/二:暴力解法
此题最先也是最容易想到的是暴力解法,但是实践证明,在 Java 提交中通不过,逐一判断超时,增加条件即满足首尾相等在进行判断相等,即可优化解,提交可以通过。
方法三:逐一比较子字符串
通过对暴力解分析,利用 Java 字符串截取方法,通过逐一比较子字符串可得。
方法四:双指针法
前三种方法实质都是通过逐一比较子字符串求解,其实还有更进一步优化,分析发现其实并不是所有长度为 needle.length() 需要比较,可以利用双指针判断,具体做法是:定义两个指针 p,q 分别指向 haystack,needle,从首字符开始,如果不相等,则移动 p;如果两个指针指向相等,则同时移动下一位,直至 p 指向 needle 的尾字符,如果仍相等,则说明找到其位置,程序结束;否则需要从不相等的位置开始同时向前回溯(p 再次指向 needle 的首字符为止);如此循环即可。
方法五:Rabin Karp 算法
Rabin Karp 算法思路是先生成窗口内子串的哈希码,然后再跟 needle 字符串的哈希码做比较。如何在常数时间生成子串的哈希码? 这里需要涉及到滚动哈希:常数时间生成哈希码,利用滑动窗口的特性,每次滑动都有一个元素进,一个出,生成一个长度为 L 数组的哈希码,需要 $O(L)$ 时间。算法步骤如下:
计算子字符串
haystack.substring(0, L)和needle.substring(0, L)的哈希值。从起始位置开始遍历:从第一个字符遍历到第 N - L 个字符;
根据前一个哈希值计算滚动哈希;
如果子字符串哈希值与
needle字符串哈希值相等,返回滑动窗口起始位置。返回 -1,这时候
haystack字符串中不存在needle字符串。
方法六:BM算法
BM(Boyer-Moore)算法思想是有模式串中不存在的字符,那么肯定不匹配,往后多移动几位,提高效率,遵循坏字符规则,好后缀规则。
1)坏字符规则:当文本串中的某个字符跟模式串的某个字符不匹配时,称文本串中的这个失配字符为坏字符,此时模式串需要向右移动,移动的位数 = 坏字符在模式串中的位置 - 坏字符在模式串中最右出现的位置。此外,如果”坏字符”不包含在模式串之中,则最右出现位置为-1;
2)好后缀规则:当字符失配时,后移位数 = 好后缀在模式串中的位置 - 好后缀在模式串上一次出现的位置,且如果好后缀在模式串中没有再次出现,则为-1。
本题采用坏字符规则,具体做法是:首先针对模式串 needle 构造模式串的数组表(哈希表) suffix (本题是字符串默认为基本字符,ASCII 码是8位),然后从 haystack 的首字符循环遍历长度为 needle.length() 的子串, 跳跃为 skip, 用 needle 从后往前匹配,如果整个模式串匹配成功则 skip=0 终止程序,否则 skip = j - suffix[haystack.charAt(i + j)],直到最后一个子串,如果未匹配成功,最后返回 -1。
方法七:KMP 算法
KMP (Knuth-Morris-Pratt) 算法,基本思路如下:
假设现在文本串
S匹配到i位置,模式串P匹配到j位置:1)如果
j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;2)如果
j != -1,且当前字符匹配失败(即S[i] != P[j]),则令i不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j]位。
next数组各值的含义:代表当前字符之前的字符串中,有多大长度的相同前缀后缀。例如next [j] = k,代表j之前的字符串中有最大长度为k的相同前缀后缀。
算法步骤:首先求解模式串 P 的 next 数组:定义长度为 P.length() 的数组 next,遍历模式串 P,取 i=-1,j=0,若 P.charAt(j) 与 P.charAt(i) 相等,则 j 的下一个跳到 i 的下一个处,否则退回至 next[i],循环结束即可得next 数组;然后同时循环遍历文本串 S 和 模式串 P ,根据上述思路即可完成。
方法八:Sunday 算法
Sunday算法,是 Daniel M.Sunday 于1990年提出的字符串模式匹配,其核心思想是:在匹配过程中,模式串发现不匹配时,算法能跳过尽可能多的字符以进行下一步的匹配,从而提高了匹配效率。Sunday 算法思想跟 BM 算法很相似,在匹配失败时关注的是文本串中参加匹配的最末位字符的下一位字符,如果该字符没有在匹配串中出现则直接跳过,即移动步长= 匹配串长度+1;否则,同 BM 算法一样其移动步长=匹配串中最右端的该字符到末尾的距离+1。
算法步骤:定义模式串的哈希表(本题采用数组),循环遍历 haystack,每次取长度为 needle.length() 的子串与needle比较,如果相等则返回对应的下标,程序结束;否则,判断 haystack.charAt(i + needle.length()) 是否在 needle 中:若在则移动步长 skip 为1;若不在,则移动步长 skip 为 i + needle.length(),直到最后一个子串,如果未匹配成功,最后返回 -1。
测试用例组
1)
haystack= “hello“,needle= “ll“2)
haystack= “aaaaa“,needle= “bba“3)
haystack= “a“,needle= “a“4)
haystack= “aaa“,needle= “aaaa“5)
haystack= “mississippi“,needle= “a“6)
haystack= “mississippi“,needle= “issi”
参考代码
方法一:暴力解法
暴力解法,[提交时,超出时间限制],其时间复杂度为 $O(n^2)$,空间复杂度为 $O(1)$。
1 | class Solution { |
- 运行结果如下:

方法二:暴力优化解法
- 暴力优化解法,其时间复杂度为 $O(n^2)$,空间复杂度为 $O(1)$。
1 | class Solution { |
- 运行结果如下:
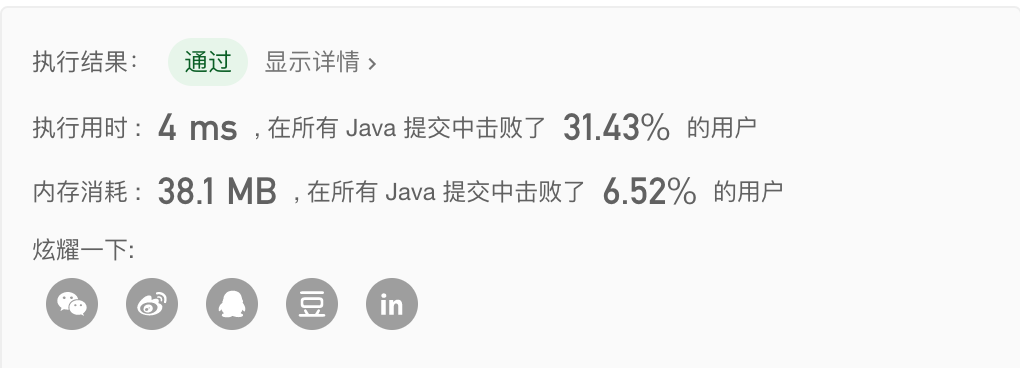
方法三:字符串截取+逐一比较子字符串
- 字符串截取+逐一比较子字符串,其时间复杂度为 $O(n)$,空间复杂度为 $O(1)$。
1 | class Solution { |
- 运行结果如下:

方法四:双指针法
- 双指针法,其时间复杂度为 $O(n)$,空间复杂度为 $O(1)$。
1 | class Solution { |
- 运行结果如下:

方法五:Rabin Karp 算法
Rabin Karp算法,其时间复杂度为 $O(n)$,空间复杂度为 $O(1)$。
1 | class Solution { |
- 运行结果如下:

方法六:BM 算法
BM算法,其时间复杂度为 $O(n^2)$,空间复杂度为 $O(n)$。
1 | class Solution { |
- 运行结果如下:
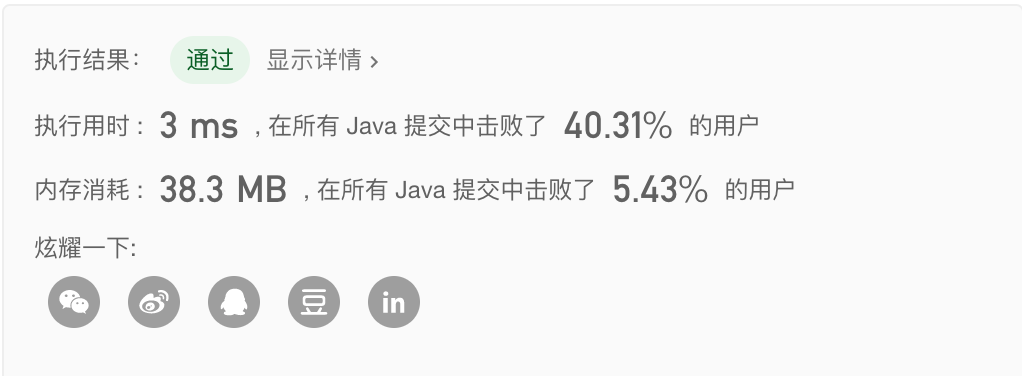
方法七:KMP 算法
KMP算法,其时间复杂度为 $O(n)$,空间复杂度为 $O(n)$。
1 | class Solution { |
- 运行结果如下:

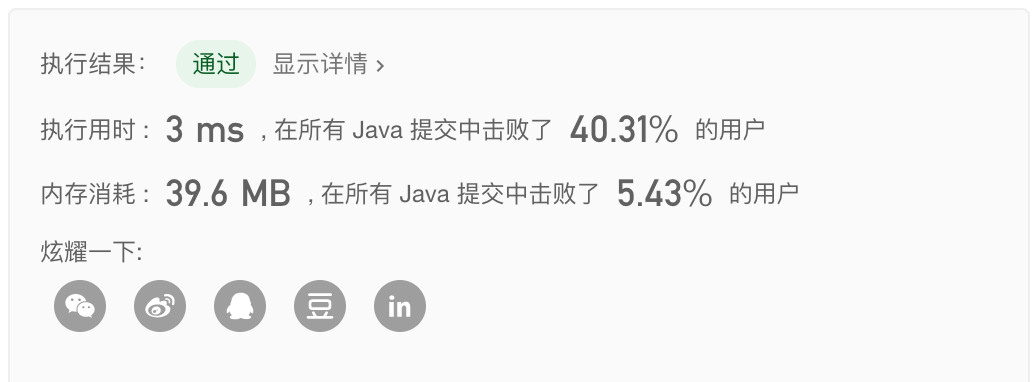
方法八:Sunday 算法
Sunday算法,其时间复杂度为 $O(n)$,空间复杂度为 $O(n)$。
1 | class Solution { |
- 运行结果如下:
参考资料
吐血整理不容易,欢迎各位扩展和补充,多多交流~

