本系列为《模式识别与机器学习》的读书笔记。
一,概率生成式模型
⾸先考虑⼆分类的情形。类别 $\mathcal{C}_1$ 的后验概率可以写成
其中,
$\sigma(a)$ 称之为 logistic sigmoid函数 。
如图4.12,logistic sigmoid函数 $\sigma(a)$ 的图像, ⽤红⾊表⽰,同时给出的是放缩后的逆probit函数 $\Phi(\lambda a)$ 的图像, 其中 $\lambda^2=\frac{\pi}{8}$ , ⽤蓝⾊曲线表⽰。
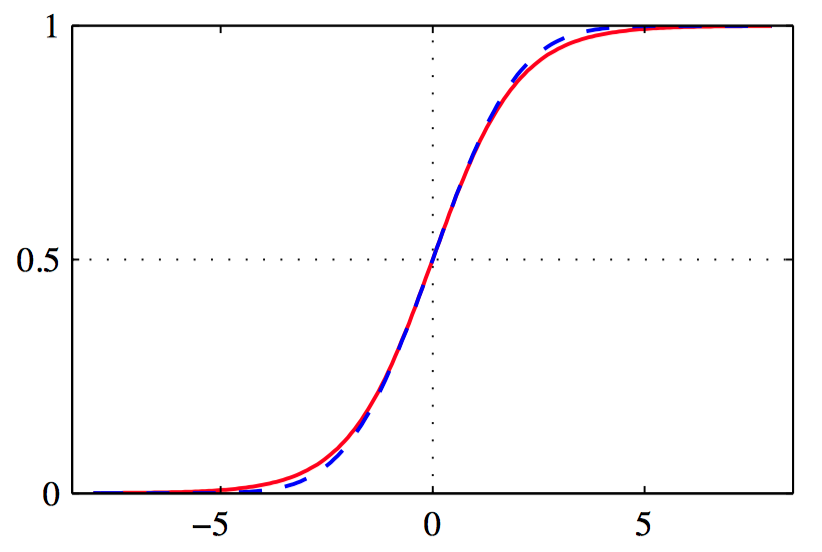
logistic sigmoid函数 在许多分类算法中都有着重要的作⽤,满⾜下⾯的对称性
logistic sigmoid的反函数为
被称为 logit函数。它表⽰两类的概率⽐值的对数 $\ln[\frac{p(\mathcal{C}_1|\boldsymbol{x})}{p(\mathcal{C}_2|\boldsymbol{x})}]$ ,也被称为 log odds函数 。
对于 $K > 2$ 个类别的情形,有
被称为归⼀化指数(normalized exponential),也叫 softmax函数 ,可以被当做logistic sigmoid函数对于多类情况的推⼴。其中, $a_k$ 被定义为
如果对于所有的 $j\ne k$ 都有 $a_k \gg a_j$ ,那么 $p(\mathcal{C}_k|\boldsymbol{x})\simeq 1$ 且 $p(\mathcal{C}_j|\boldsymbol{x}) \simeq 0$。
1,连续输⼊
假设类条件概率密度是⾼斯分布,然后求解后验概率的形式。假定所有的类别的协⽅差矩阵相同,这样类别 $\mathcal{C}_k$ 的类条件概率为
⾸先考虑两类的情形。根据公式(4.36),有
其中,
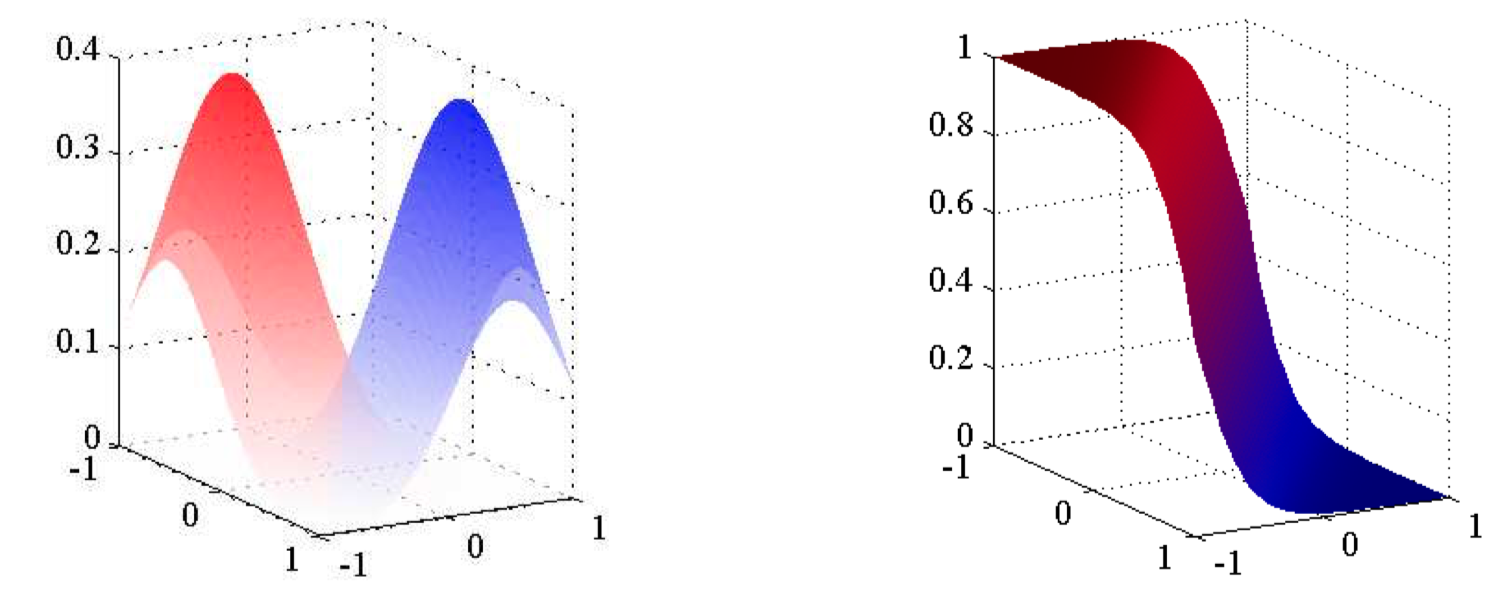
如图4.13,左图给出了两个类别的类条件概率密度,分别⽤红⾊和蓝⾊表⽰。 右图给出了对应的后验概率分布 $p(\mathcal{C}_1|\boldsymbol{x})$ , 它由 $\boldsymbol{x}$ 的线性函数的 logistic sigmoid 函数给出。 右图的曲⾯的颜⾊中, 红⾊所占的⽐例由 $p(\mathcal{C}_1|\boldsymbol{x})$ 给出,蓝⾊所占的⽐例由 $p(\mathcal{C}_2|\boldsymbol{x})=1-p(\mathcal{C}_1|\boldsymbol{x})$ 给出。
对于 $K$ 个类别的⼀般情形,根据公式(4.39),有
其中,
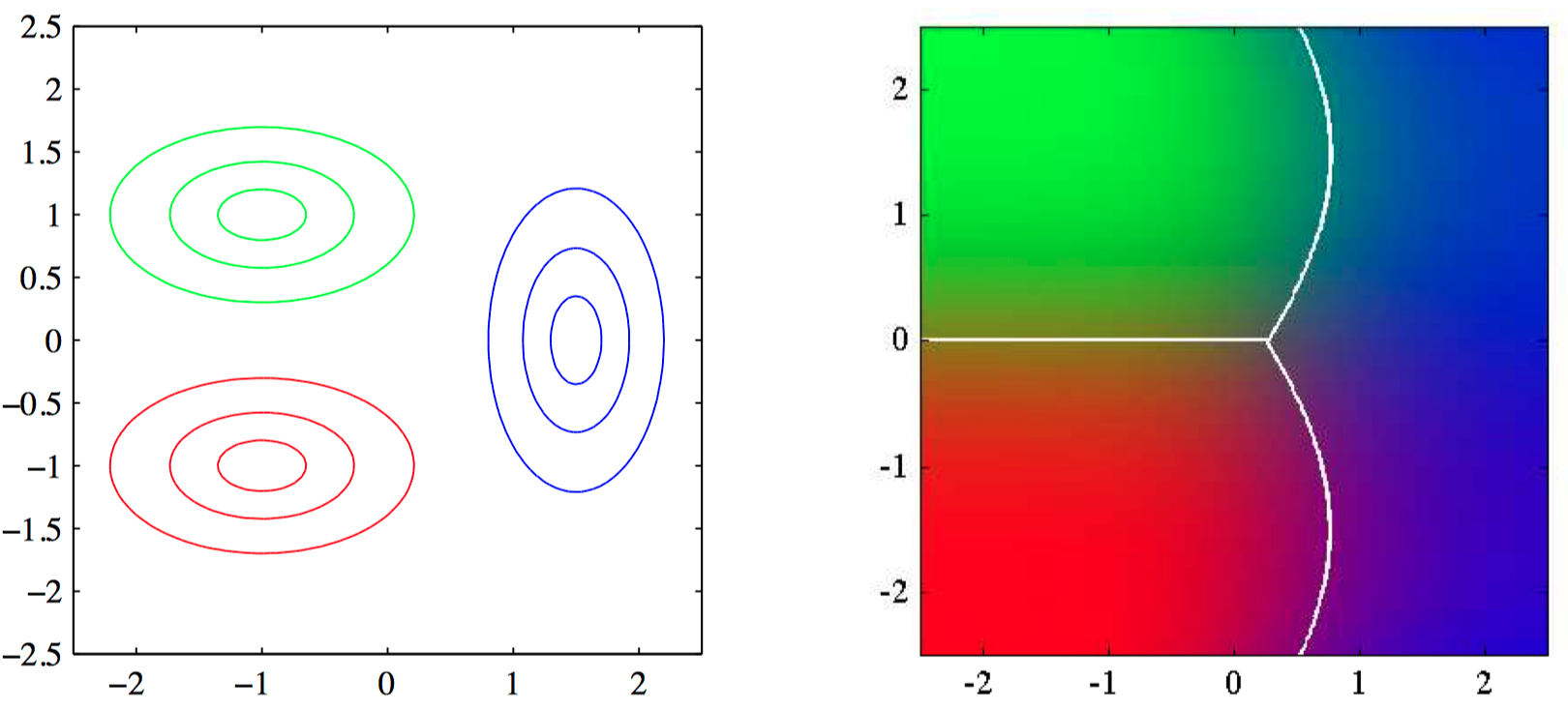
如图4.14,左图给出了三个类别的类条件概率密度,每个都是⾼斯分布,分别⽤红⾊、绿⾊、蓝⾊表⽰,其中红⾊和绿⾊的类别有相同的协⽅差矩阵。右图给出了对应的后验概率分布,其中 $RGB$ 的颜⾊向量表⽰三个类别各⾃的后验概率。决策边界也被画出。注意,具有相同协⽅差矩阵的红⾊类别和绿⾊类别的决策边界是线性的,⽽其他类别之间的类别的决策边界是⼆次的。
2,最⼤似然解
⾸先考虑两类的情形,每个类别都有⼀个⾼斯类条件概率密度,且协⽅差矩阵相同。假设有⼀个数据集 $\{\boldsymbol{x}_n, t_n\}$ ,其中 $n = 1,\dots,N$ 。这⾥ $t_n = 1$ 表⽰类别 $\mathcal{C}_1$ ,$t_n=0$ 表⽰类别 $\mathcal{C}_2$ 。 把先验概率记作 $p(\mathcal{C}_1)=\pi$ , 从⽽ $p(\mathcal{C}_2)=1-\pi$ 。 对于⼀个来⾃类别 $\mathcal{C}_1$ 的数据点 $\boldsymbol{x}_n$ , 有 $t_n = 1$ ,因此
类似地,对于类别 $\mathcal{C}_2$ ,有 $t_n = 0$ ,因此
于是似然函数为
其中,$\mathbf{t}=(t_1,\dots,t_n)^{T}$ 。
⾸先考虑关于 $\pi$ 的最⼤化,对数似然函数中与 $\pi$ 相关的项为
令其关于 $\pi$ 的导数等于零,整理,可得
其中 $N_1$ 表⽰类别 $\mathcal{C}_1$ 的数据点的总数,⽽ $N_2$ 表⽰类别 $\mathcal{C}_2$ 的数据点总数。
现在考虑关于 $\mu_1$ 的最⼤化,把对数似然函数中与 $\mu_1$ 相关的量挑出来,即
令它关于 $\mu_1$ 的导数等于零,整理可得
通过类似的推导,对应的 $\mu_2$ 的结果为
最后,考虑协⽅差矩阵 $\boldsymbol{\Sigma}$ 的最⼤似然解。选出与 $\boldsymbol{\Sigma}$ 相关的项,有
其中,
使⽤⾼斯分布的最⼤似然解的标准结果,我们看到 $\boldsymbol{\Sigma} = \boldsymbol{S}$ ,它表⽰对⼀个与两类都有关系的协⽅差矩阵求加权平均。
3,离散特征
⾸先考察⼆元特征值 $x_i\in\{0, 1\}$ ,如果有 $D$ 个输⼊,那么⼀般的概率分布会对应于⼀个⼤⼩为 $2^D$ 的表格,包含 $2^D−1$ 个独⽴变量(由于要满⾜加和限制)。由于这会 随着特征的数量指数增长,因此我们想寻找⼀个更加严格的表⽰⽅法。这⾥,我们做出朴素贝叶斯(naive Bayes)的假设,这个假设中,特征值被看成相互独⽴的,以类别 $\mathcal{C}_k$ 为条件。因此得到类条件分布,形式为
其中对于每个类别,都有 $D$ 个独⽴的参数,有
这是输⼊变量 $x_i$ 的线性函数。
4,指数族分布
使⽤指数族分布的形式,可以看到 $\boldsymbol{x}$ 的分布可以写成
现在把注意⼒集中在 $\boldsymbol{\mu}(\boldsymbol{x})=\boldsymbol{x}$ 这种分布上,引⼊⼀个缩放参数 $s$,这样就得到了指数族类条件概率分布的⼀个⼦集
注意让每个类别有⾃⼰的参数向量 $\boldsymbol{\lambda}_k$ ,并且假定各个类别有同样的缩放参数 $s$ 。
对于⼆分类问题,把这个类条件概率密度的表达式代⼊相关公式,计算后可得后验概率是⼀个作⽤在线性函数 $a(\boldsymbol{x})$ 上的logistic sigmoid函数。$a(\boldsymbol{x})$ 的形式为
类似地,对于 $K$ 类问题,有
这又是⼀个 $\boldsymbol{x}$ 的线性函数。
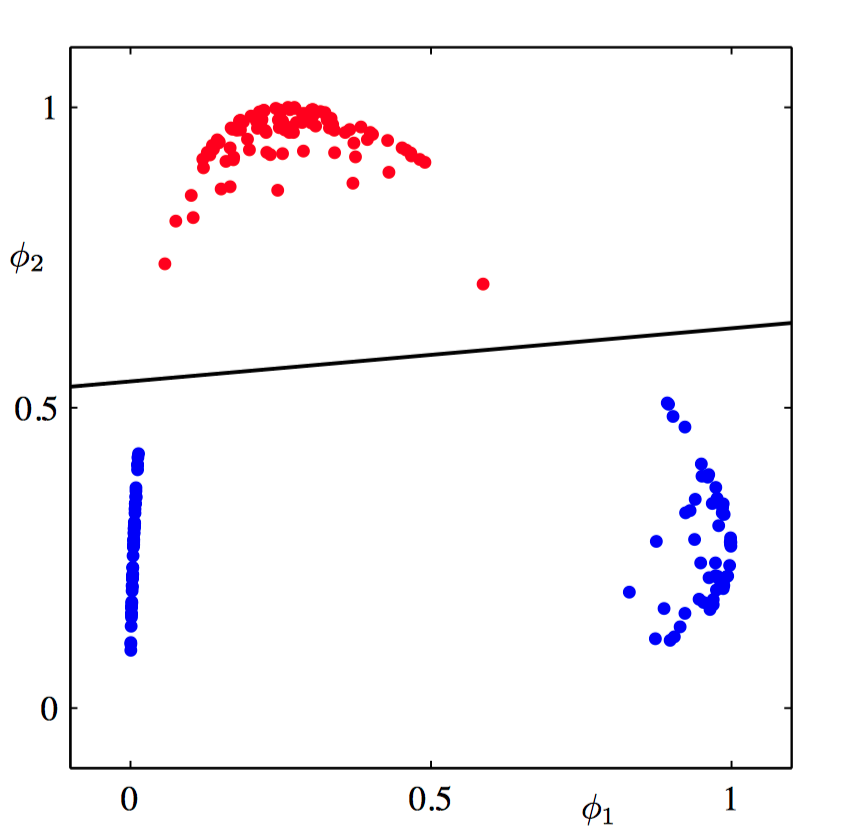
如图4.15,线性分类模型的⾮线性基函数的作⽤的说明。下图给出了原始的输⼊空间 $(x_1,x_2)$ 以及标记为红⾊和蓝⾊的数据点。这个空间中定义了两个“⾼斯”基函数 $\phi_1(\boldsymbol{x})$ 和 $\phi_2(\boldsymbol{x})$ ,中⼼⽤绿⾊⼗字表⽰,轮廓线⽤绿⾊圆形表⽰。
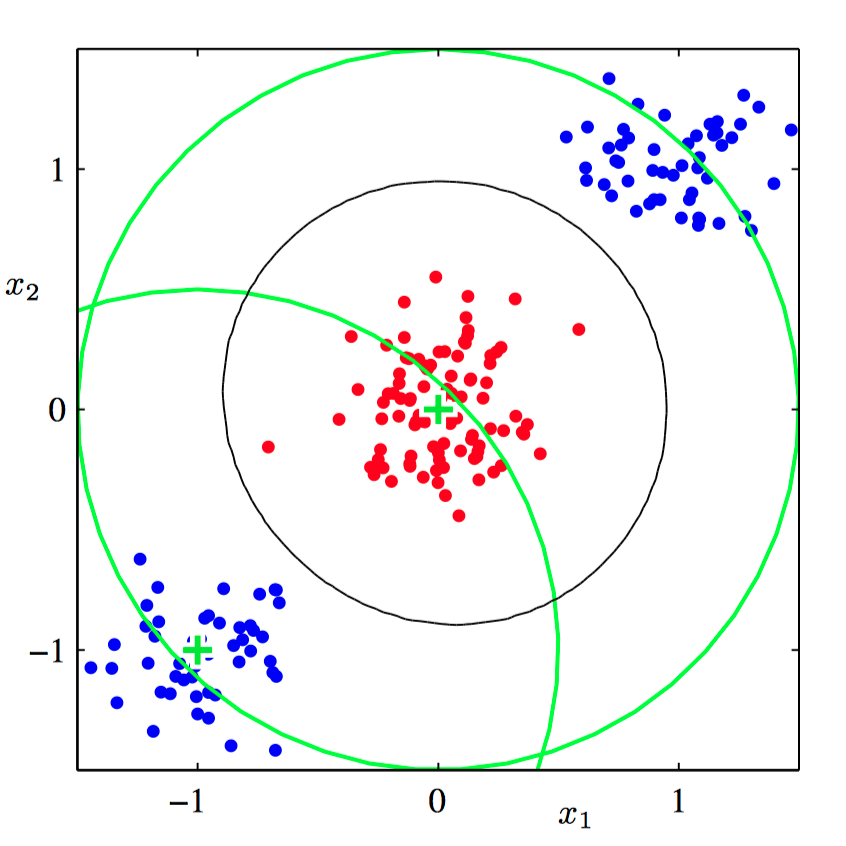
如图4.16,对应图4.15中的特征空间 $(\phi_1,\phi_2)$ 以及线性决策边界。
二,贝叶斯logistics回归
对于logistic回归,精确的贝叶斯推断是⽆法处理的。特别地,计算后验概率分布需要对先验概率分布于似然函数的乘积进⾏归⼀化,⽽似然函数本⾝由⼀系列logistic sigmoid函数的乘积组成,每个数据点都有⼀个logistic sigmoid函数,对于预测分布的计算类似地也是⽆法处理的。
1, 拉普拉斯近似
由于寻找后验概率分布的⼀个⾼斯表⽰,因此在开始的时候选择⾼斯先验是很⾃然的。故把⾼斯先验写成⼀般的形式
其中 $\boldsymbol{m}_0$ 和 $\boldsymbol{S}_0$ 是固定的超参数。 $\boldsymbol{w}$ 的后验概率分布为
其中 $\mathbf{t} = (t_1,\dots, t_N)^{T}$ 。两侧取对数,然后代⼊先验分布,对于似然函数,有
其中 $y_n=\sigma(\boldsymbol{w}^{T}\boldsymbol{\phi}_n)$ 。为了获得后验概率的⾼斯近似,⾸先最⼤化后验概率分布,得到MAP(最⼤后验)解 $\boldsymbol{w}_{WAP}$ ,定义了⾼斯分布的均值,这样协⽅差就是负对数似然函数的⼆阶导数矩阵的逆矩阵,形式为
后验概率分布的⾼斯近似的形式为
2, 预测分布
给定⼀个新的特征向量 $\boldsymbol{\phi}(\boldsymbol{x})$ ,类别 $\mathcal{C}_1$ 的预测分布可以通过对后验概率 $p(\boldsymbol{w} | \mathbf{t})$ 积分,后验概率本⾝由⾼斯分布 $q(\boldsymbol{w})$ 近似,即
且类别 $\mathcal{C}_2$ 的对应的概率为 $p(\mathcal{C}_2|\boldsymbol{\phi},\mathbf{t})=1-p(\mathcal{C}_1|\boldsymbol{\phi},\mathbf{t})$ 。为了计算预测分布,⾸先注意到函数 $\sigma(\boldsymbol{w}^{T}\boldsymbol{\phi})$ 对于 $\boldsymbol{w}$ 的依赖只通过它在 $\boldsymbol{\phi}$ 上的投影⽽实现。记 $a=\boldsymbol{w}^{T}\boldsymbol{\phi}$,有
其中 $\delta(·)$ 是 狄拉克Delta函数 。由此有
其中,
计算 $p(a)$ :注意到Delta函数给 $\boldsymbol{w}$ 施加了⼀个线性限制,因此在所有与 $\boldsymbol{\phi}$ 正交的⽅向上积分,就得到了联合概率分布 $q(\boldsymbol{w})$ 的边缘分布。
通过计算各阶矩然后交换 $a$ 和 $\boldsymbol{w}$ 的积分顺序的⽅式计算均值和协⽅差,即
注意,$a$ 的分布的函数形式与线性回归模型的预测分布相同, 其中噪声⽅差被设置为零。因此对于预测分布的近似变成了
使⽤ 逆probit函数 的⼀个优势是:它与⾼斯的卷积可以⽤另⼀个逆probit函数解析地表⽰出来。 特别地,可以证明
现在将逆probit函数的近似 $\sigma(a)\simeq\Phi(\lambda a)$ 应⽤于这个⽅程的两侧, 得到下⾯的对于logistic sigmoid函数与⾼斯的卷积近似
其中,
得到了近似的预测分布,形式为

